PDF version of this entire document
PDF version of this entire document
Moving on to some proper caching, there are issues to overcome. As we don't have the code entirely, recovery was needed. A software cache in C with matlab interface was used along with fast marching in C (with matlab interface supporting separate grid initialization and computation). The idea is to get a better resolution approach working, but it requires studying our programs as we then need to merge these changes with the mainline. Having re-fetched the latest version, we shall merge.
To summarise modification with a quick report, changes were as follows. Taking one portion at the time, we have been find'ing, diff'ing and grep'ing corresponding files that come from GIP SVN and the SVN tree at TAU, which comprises ANN, Cache, FastMarching, and Remesh (a subset of the whole).
Cache and FastMarching are the main components that have been adapted to facilitate caching and upon a cursory check, other parts too have some interesting inherent changes that might cause incompatibilities, probably a result of many people - myself included - changing the code somewhat and hacking our code accordingly. Compiling on the server is slightly complicated by the fact that the server uses 64-bit Ubuntu and not Windows (ANN is already compiled and remeshing works too). Currently, code is being changed somewhat to make the rest compilable as everything else has been prepared and tested, so it ought to take hours to mend.
We finally compiled FMM successfully, although with the following compromises:
__inline, __forceinline etc. got removed as the compiler does not support them. It ought to be possible force 'inline' with GCC or ICC, but it would take further work that may not be a top priority.
The StrCmpI function (Windows) is not supported, so we use StrCmp instead. The same goes for some preprocessors and type definitions that needed to be rewritten in an ISO C++-compatible way.
Finally, attempts to cast fmm to `unsigned int' made the compiler very angry, insisting that it loses precision perhaps because it assumes we are compiling 32-bit code on 64-bit machine. So anyway, we changed that to long.
If any of this is critically problematic, this might resurface later.
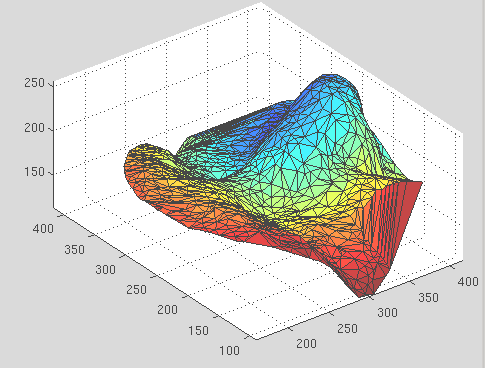
All the relevant code has been successfully compiled on GNU/Linux (after many minor modifications) and joined together with older code, including the C++ stress minimiser. Debugging is necessary as there are still program crashes (binaries taking down the whole MATLAB session) and some opaque errors at times. An 'init' called in Fast Marching works as expected, but 'march' causes issues. Heading back to the case example tested with a sample surface, it gives the crash reports which are still under investigation.
Debugging
The fast marching code hosted by TAU insists on a triangles array that contains int32 data, unlike the analogous GIP versions (there are several lying around, which can be very confusing). Some use double and casts spuriously. Insisting on trying to make it work resulted in freezing (infinitely-running loop or another unrecoverable error) as opposed to a crash (both fatal), so there is no point to debugging using that path.
Trying to investigate things a little differently, another dataset - this time the Swiss role - is tested using the newer/enhanced FMM binary.
>> surface=swiss
surface = TRIV: [1024x3 double] X: [561x1 double] Y: [561x1 double] Z: [561x1 double] D: [561x561 double]
>> which fastmarchmex
/home/schestow/pcafaces/Imported/cached-GMDS/FastMarching/fastmarchmex.mexa64
>> f = fastmarchmex('init', int32(surface.TRIV-1), int32(surface.X(:)), int32(surface.Y(:)), int32(surface.Z(:)));
this one too 'freezes', but works OK when cast as double. In fact, the whole process works OK, so the binary I created this morning (based on Kimmel's implementation with support that separates initialisation and computation) certainly works OK for certain data, just not for Michael0, at least not at this stage. The important thing is that it does work and helps produce nice graphics (more on that later).
Experimentation with the improved Fast Marching binary showed a consistent behaviour where the expected results are sometimes obtained and sometimes the program just crashes. More specifically, while it can be shown that everything works for simple data such as the Swiss roll, for more complex data such as faces from the NIST (FRGCv2) and Texas datasets (newer Texas3DFR), the program sometimes uses up 100% of the CPU core and hangs in there with an error indicating non-ending loop in the B&B algorithm (see below). Upon a second attempt - after recovery by interruption of the process - the program crashes at an earlier stage (apparent hardware exception), which is probably not as fatal as by that stage the program is already in an unfamiliar state. The successful runs with simpler data are reproducible, so further testing is likely to help resolve this.
Narrowing data paths down a bit, it is clear that while FMM produce
the expected results (shown in Figure ![[*]](/IMG/latex/crossref.png) is one triangulated mesh, which is as coarse as it has always been),
it is the coarse correspondence stage which struggles to complete.
This is most likely a compatibility issue which further testing will
resolve shortly. Some types and interfaces have changed a little and
this needs merging elegantly. It is not entirely clear how to deal
with the case of multiple or single,
for example, without building two separate binaries (as currently
stored in SVN).
is one triangulated mesh, which is as coarse as it has always been),
it is the coarse correspondence stage which struggles to complete.
This is most likely a compatibility issue which further testing will
resolve shortly. Some types and interfaces have changed a little and
this needs merging elegantly. It is not entirely clear how to deal
with the case of multiple or single,
for example, without building two separate binaries (as currently
stored in SVN).
Note that the continuation that you make by linking the cheeks (with very long) triangles may be painful for the FMM.
When running experiments I always move the GUI sliders to include the cheeks (convex and not concave). Some toy examples still exclude the cheeks. Today was spent narrowing down the cause of the crash probably to a recursion whose exit condition is never reached. This recursive procedure can be limited by two or three unfolding of the triangles. If these are good triangles, then it should work. Else, something could happen with the boundaries. It takes a while to debug because each failure is fatal and requires restarting the whole of MATLAB. Two desktops (spread across three monitors) and one GIP server are used for debugging this. While one crash occurs, the other desktop is meanwhile loading up another instance of MATLAB. Each crash is verbose but gives very little information that is coherent or programmer-readable. So the testing is very trial-and-error-ish by nature.
One is a binary optimised to calculate geodesic distances of every mesh vertex from one source. The other case deals with distance matrices of pair-wise geodesic distances. In the implementations, multiple and single means distance map from a source to all points vs all-to-all. We need the first on among hose two. They are the same essentially, and it is important that we init once, and then do the computations. Grid init takes a lot of time and is valid for the entire life of a mesh.
While the full history of implementations diverging is unknown without having spent years watching the code, the most glaring difference between the version in GIP repositories and the one in TAU is that the interfaces vary somewhat. One uses an explicit init call, whereas in the other it is implicit/internal and there is also a subdivision into the two not-so-distinct cases, at least at a binary level (the MATLAB interfaces parse input and interpret which case is to be invoked).
The way the code has been modified ensures that the intermediary MATLAB file initialises explicitly and then calls the new binaries with the casting of types so as to make everything compatible. What remains unclear though is whether or not other helper functions too have been made inconsistent. Having spent the first hours/days looking at differences between identically-named files (e.g. in meshing), it seems clear that there are some unilateral changes.
Additional complication arises from the fact that the C++ stress minimiser has its own 'hacked' version of surface initialisation, which basically adds some surface property specific to the operations it needs to perform. A lot of the functionality is hookable, but the hooking mechanism is not modular, which means that the symbiosis requires manually adding/replacing lines of code. In the case of surface initialisation, there are several variants out there all sharing the exact same filename. Ideally, all code changes would be applied to one single point, perhaps with conditional statements that facilitate everyone's needs. Otherwise it increases complexity and complicates testing in general. The FMM MATLAB executable, for example, has several names, such as fastmarchmex, fastmarch_mex, fastmarch1_mex (each doing something different and using different input arguments, requiring multiple stages/phases/function calls, etc).
Initialising moderate sized surfaces for fastmarchmex (TAU SVN) does not take long. Currently, provided nothing crashes, the problem occurs in bnb, which never terminates and does not provide much feedback indicative of the actual problem. Trying to add simple debugging cruft to the function somehow results in crashes every single time, which is mysterious and time-consuming. Attempting to debug in other functions, even by altering to-be-interpreted code rather than to-be-compiled code, leads to more persistent crashes. This is mysterious behaviour, but a segmentation fault might explain it. Given that the state of a program (e.g. what it ran beforehand) can determine whether it will crash or not, reinforces the suspicion that there needs to be refactring and it is likely that functions entirely separate from triangulated FMM are somewhat baffled, e.g. by input data types. One function deals with doubles and another with 32-bit integers. This is entirely separate from the aforementioned problem compiling the code for a 64-bit machine, where pointers to memory were insufficiently expressive (it would be best to use versatile UInt_Ptr or Int_Ptr for those).
Here is what is known for sure. The new Fast Marching implementation
works correctly and without difficulties on simple data. This morning
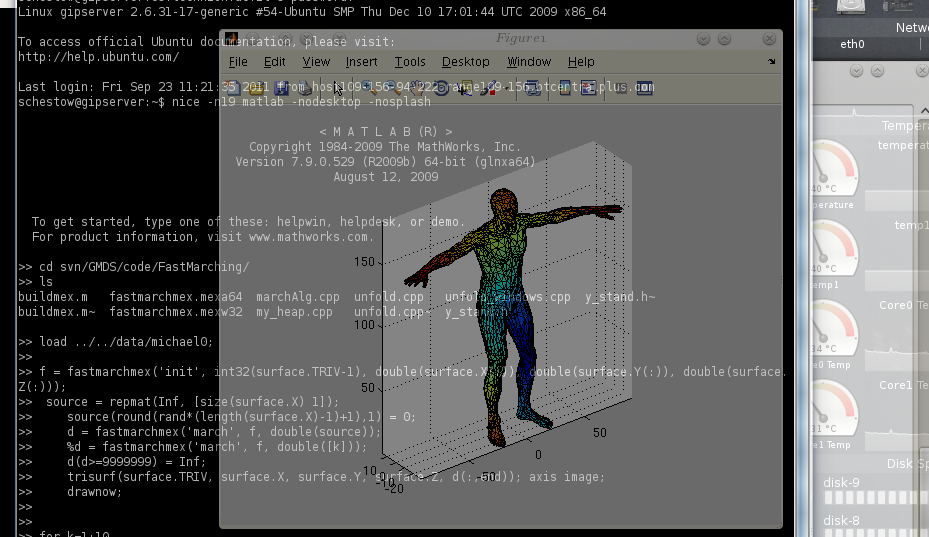
we managed to make it work correctly with michael0 as well (this is
the full body surface, as shown in the screenshot inside Figure ).
Once the function is applied to Texas/NIST data and output of this
process is piped into the coarse correspondence phase, something is
amiss. Moreover, stability is somewhat of a concern, although it's
not yet clear if memory allocation plays a role in that.
It would be most preferable to understand how implementations of FMM vary and how to tackle the fragmentation so as to reduce or altogether eliminate complexity (somewhat daunting to someone who is unfamiliar with these SVN trees). That probably ought to include some consensus on data types because functions that include precompiled binaries come to depend on these (preconditions). If the cache from Patrick Audley is 'merged' in (or made dependent rather), then it would be ideal to make it usable with all different FMM cases - everything in one fell swoop.
Management of the source code could probably be improved somewhat. It seems like everyone still uses the TOSCO implementation of GMDS (2009), which is essentially a demo. Corresponding files exist on the GIP storage server but probably not in SVN. This means that a lot of collaboration on merges remains a missed opportunity. Sometimes changes are applied to SVN which render particular source files impossible to compile (as happened a few months back), which shows the downsides too.
The nature of development when each person pushes a reference implementation in a particular direction to study the impact (researching by modification) means that a lot of code gets changed and stored locally without being pushed upstream. For some, this means having all sorts of mutually incompatible but similar chunks of files with only one central point (e.g. Web site, SVN tree, or several if different departments have different SVN repositories) from which to check out an elegant implementation which was more thoroughly tested. Part of the current project would benefit greatly from fusion of several pertinent things which may - in due course - include caching as standard and thus obliterate a known caveat (currently, GMDS limits itself by raising an exception based on the number of vertices).
Looking at the project which deals with GMDS as a similarity measure, it very much depends on annulling the restriction that leaves us making a comparison based on meshes as coarse as seen before (triangulated faces with only a thousand of so discrete sample points).
As hard as it may be to believe (that the bug was so fundamental), it turns out that it too was a result of an incompatibility - one FMM implementation treating column vectors and another row vectors. This was the cause of a fatal error, and needless to say one leading to a buffer overflow that jeopardises other memory segments (security/stability issue) and has the whole session terminated without useful details given.
The functions' interfaces will need to be made more similar as they implement identical functionality in slightly divergent ways. The question is, however, in which way should these be standardised? Separation into initialisation and the rest seems more elegant, whereas one other implementation incorporates changes that add CUDA compatibility, among other things.
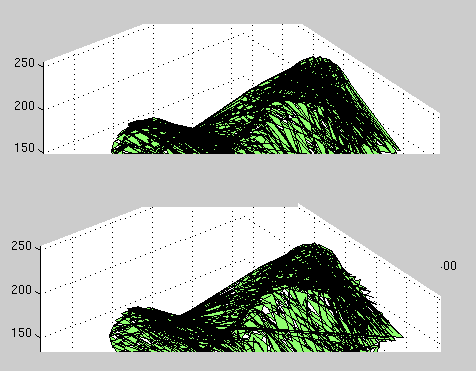
Another bug may have been spotted, which helps explain other bizarre
and inconsistent (across runs) behaviour. The triangles themselves
often get mangled, especially their faces. This breaks basic rules
which can then cause crashes as well. See Figure .
It helps to be familiar with Dijkstra algorithm for shortest path computation. It's a classic one in computer science courses (taking computer science years back to the middle of the 20th century). FMM is the same up to the update step. For most practical purposes one could ignore the unfolding part and then it's almost identical.
This is mentioned in the book Numerical geometry of non-rigid shapes (Ch. 4.2). The problem in this case seems to be purely technical although theoretical context helps identify where and why things go wrong. Once all the bugs are removed and both FMM versions work properly (either merged or separated by conditional statements), it ought to be possible to embed the caching. There are still fatal crashes, now occurring in the surface initialisation stage as investigations continue.
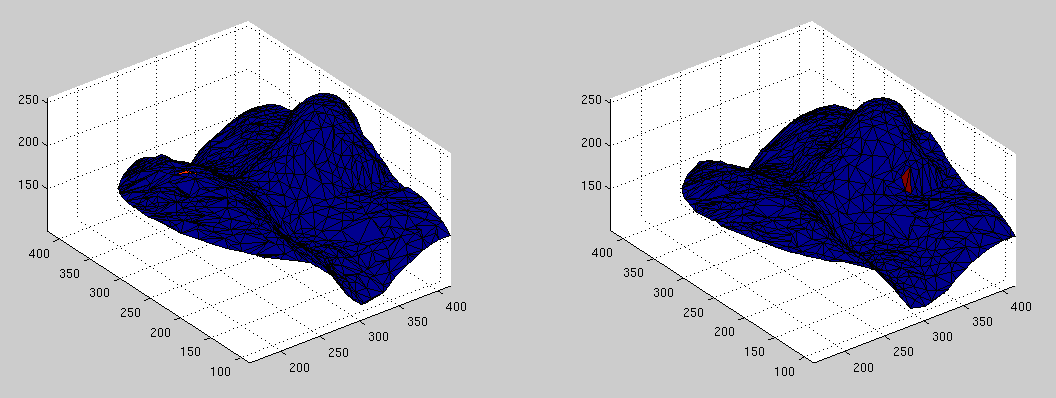
Figure shows an example of how the triangles
get all mangled (view from frontal observer).
In order to understand what we show in the middle (that mangled
view) one should recognise this simply as a bug. This too turns out
to have been the result of incompatible data types - a problem that
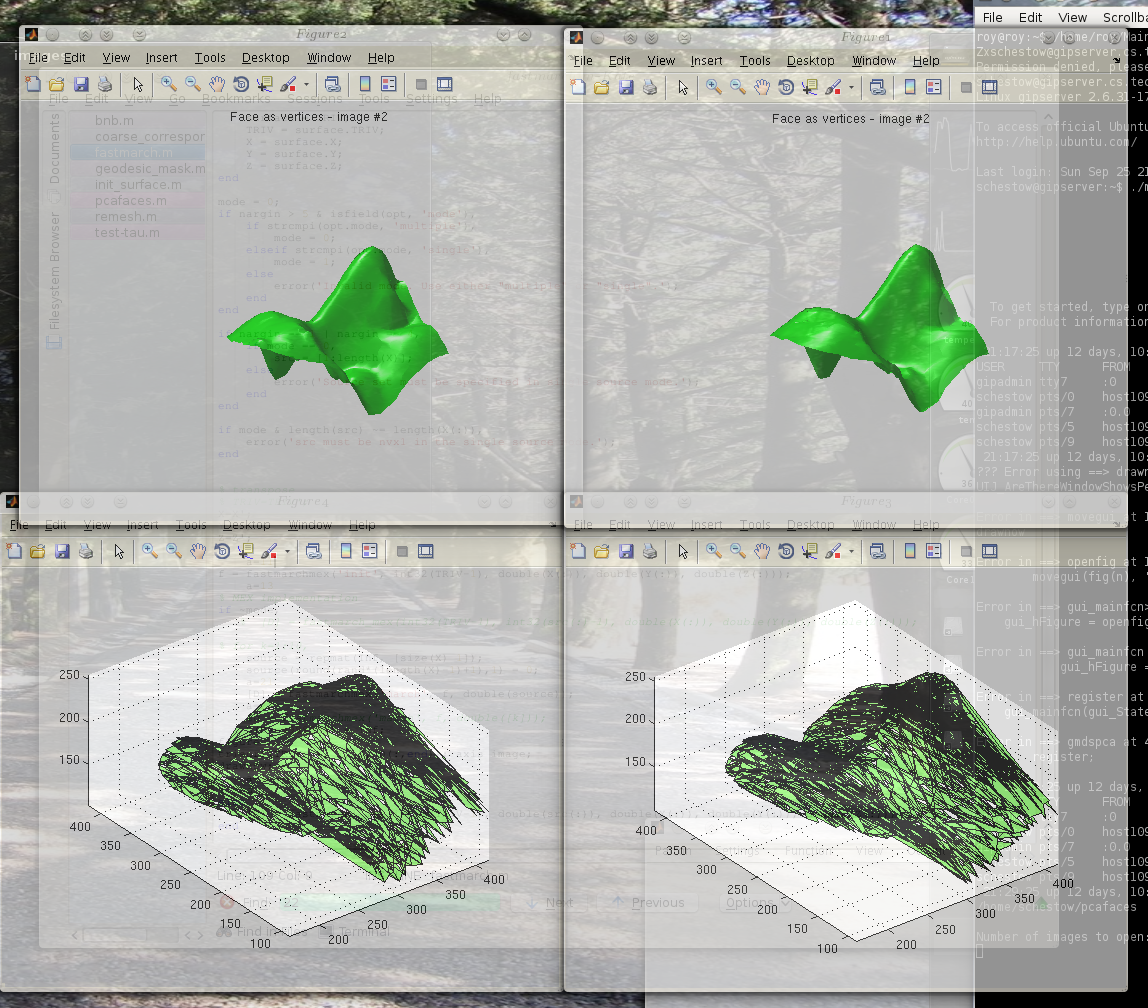
was resolved after some changes to the code. Figure
shows the problem before the fix and Figure
shows the pair after the fix (the red highlight is the source point
for D). The next problem is less fatal in that sense that
it does not crash the entire session; trying to make the code for
stress minimisation (with its own surface initialiser) compatible
with others may require careful merging.
TAU version has surface with properties as follows for TOSCO data (full body): TRIV: [3987x3 double] X: [2000x1 double] Y: [2000x1 double] Z: [2000x1 double] TRIE: [3987x3 double] ETRI: [5988x2 double] E: [5988x2 double] VTRI: {2000x1 cell} ADJV: {2000x1 cell} D: [] diam: 238.7711 nv: 2000 nt: 3987 ne: 5988 genus: 1.5000.
Consolidation is made harder by the fact that implementation-wise there are fundamental differences between the object-oriented commands-driven FMM and the other implementations which are CUDA-compatible and have no classes at all (mostly imperative), namely unfold.c and unfold.cpp.
It's really an open question; what should be taken from each to make them complementary? Which implementation should supersede the others? And moreover, there seems to be an issue related to the init and deinit process for the FMM class whose constructor and destructor do not always keep the data within boundaries (data is stored with a pointer to it). This seems to have been the sole cause of crashes so far. For simple cases where little memory is in use (toy examples), this always works fine, but inside a program that allocates and uses hundreds of megabytes this becomes a major peril and debugging for MEX inside MATLAB is hard.
Roy Schestowitz 2012-01-08