PDF version of this entire document
PDF version of this entire document
Fusion of code portions gave more scalable code that uses a single
source for FMM and enables one to see how GMDS fares as a face similarity
measure, even if resolution is improved beyond the 600 or 1000 vertices,
as shown in Figure ![[*]](/IMG/latex/crossref.png) . It is important
to emphasise that all GMDS results we have ever gotten (and associated
ROC curves) are based on just 600 or 1000 vertices. It should later
on be possible to see the potential of increases, with or without
cache (there are other tricks of the trade available for use).
. It is important
to emphasise that all GMDS results we have ever gotten (and associated
ROC curves) are based on just 600 or 1000 vertices. It should later
on be possible to see the potential of increases, with or without
cache (there are other tricks of the trade available for use).
We have been pushing it hard to get high recognition rates (with increased resolution, refined boundaries, etc.) since the end of July to make it more commercially viable and competitive wrt other algorithms (and thus publishable) and if these resolution gains do not help, there might be other things that can be more easily explored (without having to debug much).
Sticking with the objectives set in September, I shall try to produce a comparative analysis, e.g. using overlaid ROC curves, that gives us insight into impact on resolution on recognition performance. Curves should hopefully show that the higher the resolution, the higher the curve (nearer to the top-left corner), in which case it becomes clear that the problem is truly resolution-dependent, to an extent unknown to us at this stage.
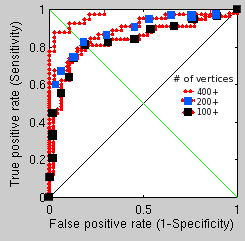
Working our up upwards, so far it is simple to demonstrate the correlation
between the number of vertices that make up the surface and the recognition
performance, as shown in Figure 's
interim (coarse) plot that will have more samples added to it. So
far, based on a very crude GMDS algorithm with just 50 points and
between 100-400+ vertices, it can be seen that recognition performance
is strongly linked to the amount of information available (no surprise
there, but a sanity check at the very least). It will be interesting
to find out at what point there is convergence/plateauing, i.e. at
what stage it no longer helps to have resolution refined. A lot of
the older experiments were run with 600-1000 vertices and those which
were better optimised could peak at around 95% recognition rate.
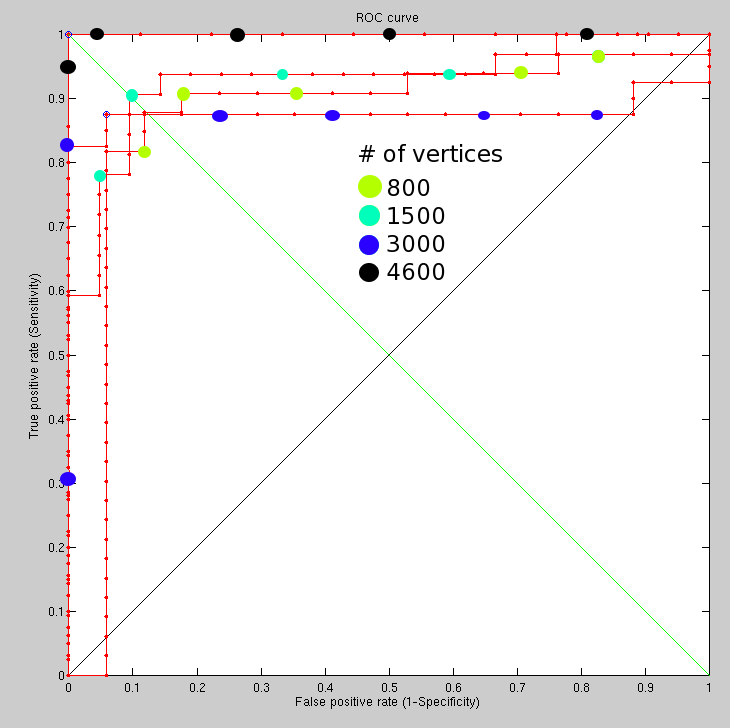
I've reached 4,600 vertices. It's plateauing somewhat at this level, however with code from Alex come some nice tricks that will shortly be incorporated to improve performance. Some values are clearly indicating match failure at GMDS level, which merits another attempt at matching (exception) rather than a final classification.
These experiments took a long time to set up and run (manually) because of some freezing and stability issues. The important thing is that they provide insight into potential of particular paths of exploration. It is quite imperative, especially for 99% recognition rate (or anywhere in that region), to eliminate all situations of topological mismatch. If those cases are removed, then exceeding 95% should be easy.
Stability is a bit of a nightmare at a resolution which translates to 4,600 vertices, unless more tricks like caching are put to use. But all in all it is still possible to pull some values out and based on 10 true pairs and 10 false pairs (randomly selected), there is perfect detection rates (although with a small sample size). What would be worth implementing is a mechanism for detecting mismatch that it topological and then retrying with different initialisation, until the score falls within some sane range, as defined in advance. This would considerably improve performance.
The combination of C++ code for stress minimisation and some improved code (which does not run too robustly on the 64-bit servers yet) has the potential for acting as a similarity measure, with ot without a training process (e.g. PCA). Performance in terms of time is not fantastic, but it is a tradeoff between accuracy and speed. The increase in the number of vertices does seem to play a real role.
Many incorrect classifications are the incorrect matching between
correct pairs, due to GMDS errors. This leads to a high false negative
rate (type II error), which can mostly be overcome with repetition
using permutation, assuming the detection exceeds some certain threshold,
which is something were implementing. The ROC curves in Figure
do not yet use this methodology.
Interesting solution was seen developing, with hope of seeing if it works. Regarding the ROC, we have flip in performances as we increase the resolution. This is a baffling reversal, but given the size of the test set (due to crashes these experiments required literally hundreds of sessions) it's more or less expected to be around the same ballpark at high resolutions. Heightening the curve (vertically) is something which should be easily achievable and is worked on at this moment. There are problematic cases - however rare - where the same person in different poses is recognised as not belonging to the same set of images.
It looks as if 3000 is worse than 800 vertices, which we do not get in 4600 vertices. 4600 vertices without some extra cashing already pushes the program to its limit, which reduces the size of the test set, but all recognitions attempted so far provide perfect separation. It would be ideal to invest time in it once the algorithm has been amended to not account for GMDS errors as image mismatches (false negatives).
We could align coarse to fine if this is the case. This hasn't been tried here before, not in the experiments shown so far, Maybe by doing a multi-resolution test we can get more reliable similarity ensemble.
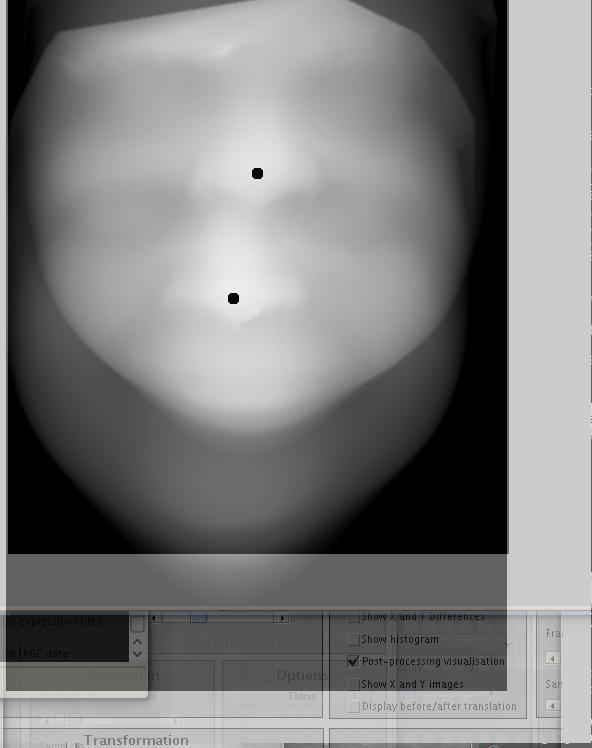
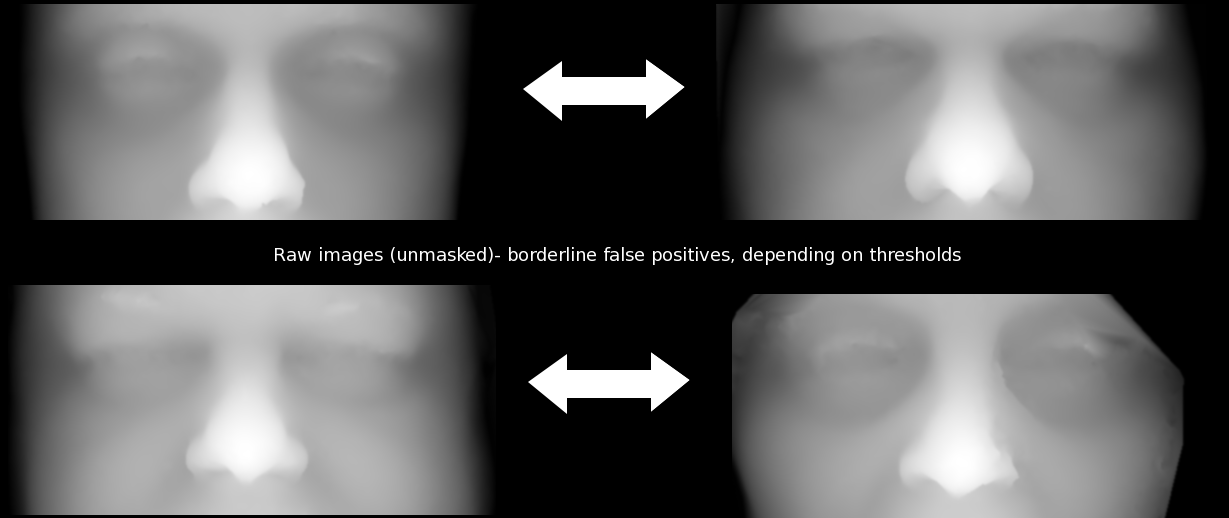
Areas of mismatch have been studied more closely in order to understand what causes them. Several large images were looked at along with the GUI (with previews of images enabled), showing quite clearly that we must remove hair from the surfaces as many mis-detections are caused by this. The hair just slips in sometimes, depending on the imaged person. We must also fix image alignment in cases where the nose tip is not accurately detected and use multiple runs, perhaps with a multi-resolution approach as an option, for ensuring correspondences have had more than one opportunity getting identified. The images from here onwards provide insight into the 'debugging' (adjustment) process, which currently utilises special cases (errors) to find essential workarounds. The aim is to get close to 99% recognition rate.
|
|
By cutting the surfaces above the eyes (still tweaking the levels), increasing the resolution, and adding a multi-resolution approach among a few other improvements, the discriminative power is now greatly increased and the 'sweet spot' seems to be approachable in the sense that the erroneous classifications get looked at closely, whereupon it usually turns out the the metadata - not the data - has mistakes in it (incorrect pairs marked as correct ones and vice versa). The borderline cases are those which require tweaking for.
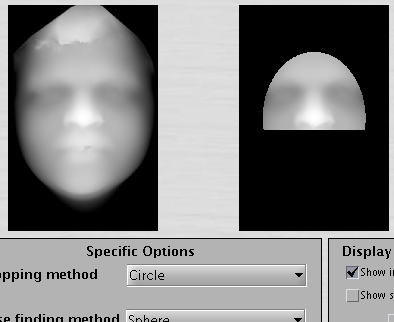
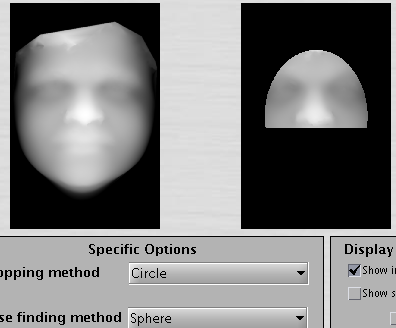
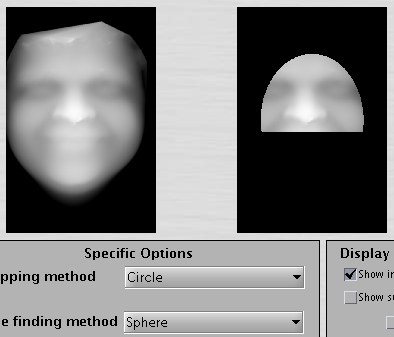
Figure shows a densely-sampled
surface without the forehead (the area above the eyebrows has components
removed because of issues associated with hair).
The sample size is not large enough for an sufficiently informative ROC curve, but there are only a few wrong classifications. One is a borderline case where pairs from different people almost seem like belonging to the same person (just almost, so separability can be further improved). The other case is mostly a case of GMDS not working, not quite a wrong classification. At all resolutions attempted so far, one pair of faces (same person imaged) cannot be made correspondent. This gets detected as an error because the values are not sane. Other than that, there is almost an order of magnitude apart in terms of separation between correct pairs and incorrect pairs. One important issue to tackle is the rare case where GMDS hardly latches onto facial features at all, as shown in Figure
and
Figure .
Roy Schestowitz 2012-01-08