PDF version of this entire document
PDF version of this entire document
GMDS matrices should be possible to obtain and perform analysis on,
but a more robust PCA process may be needed. The way everything is
presently structured, using a hybrid of measures will be trivial,
however the way data gets organised may matter (concatenation is just
one option, probably an inferior one to using a combined model which
studies the correlation within a pair of models). In order to improve
future results, a Robust Generalised PCA implementation will be attempted,
where one of the early experiments will show the difference between
classification rates when classic PCA is used, compared for instance
to a process comprising a GPCA-Voting algorithm with Robust Covariance
Estimator, Sample Influence Function, and Theoretical Influence Function.
We can test different combinations of these once everything is implemented
and properly tested. The proposed framework may not only accommodate
experiments around GMDS but also more comprehensive benchmarks providing
insight into potential steps of refinement. The improved PCA component
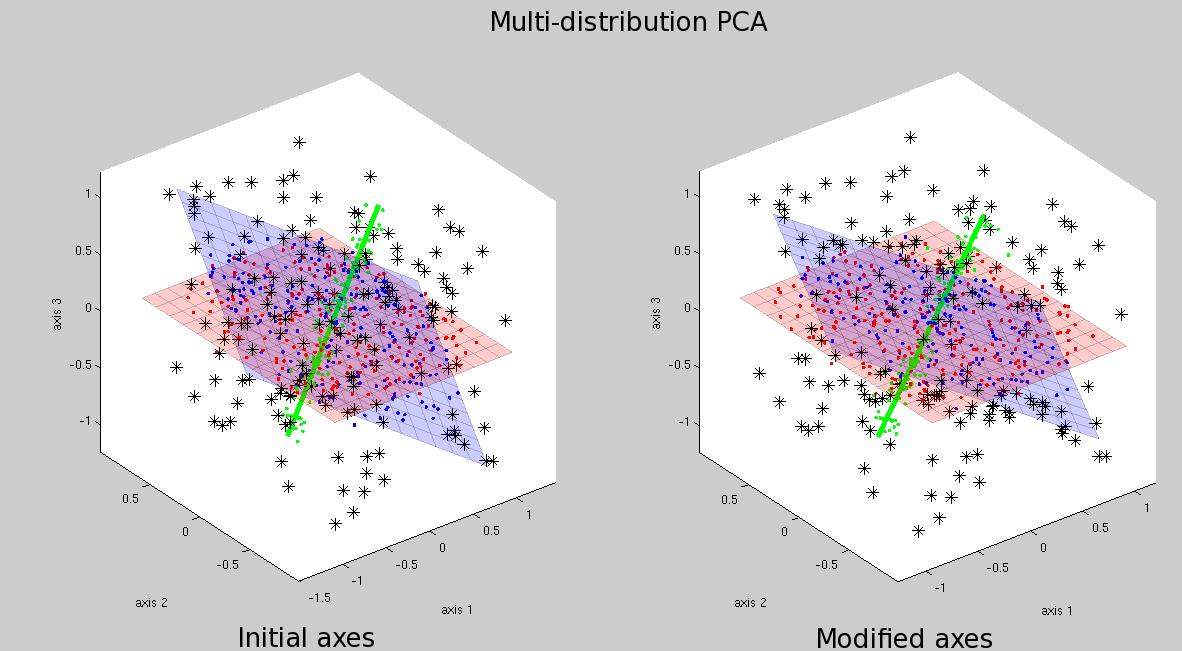
is being implemented and GMDS too will get merged in. The concept
is tested and shown in Figure ![[*]](/IMG/latex/crossref.png) .
.
Progress on GMDS with RGPCA will be described later.
Outlier detection would probably be needed in cases where samples deviate too much from known distributions and thus should be excluded or rejected, at least in model-building. It is not entirely clear, however, what applicability the division into groups of distributions (assuming no banana-shaped distributability) the generalisation will bring about, unless for example the task is to identify and also classify different shapes (e.g. dogs and horses) at the same time, classifying them both by type and by identify, i.e. inter- and intra-dissimilarity, respectively (even separating classification of people and expressions they have). It might this be the intended application, as otherwise we over-complicate everything. However, It could accelerate the way by which we do recognition (rather than identification).
Roy Schestowitz 2012-01-08