PDF version of this entire document
PDF version of this entire document
Included now is a routine hole-filling code. It's part of the program,
which also shows shape residual for debugging purposes, as shown in
Figure ![[*]](/IMG/latex/crossref.png) for example.
for example.
|
Mian's group vaguely alludes to some difficulties and workarounds that help tackle special cases of mis-detection, whereupon they use thresholds to rule out error or even the mere possibility or error (i.e. real signal which seems suspect based on algorithmic judgment).
I have begun working on the matching algorithm - that which pairs images to galleries of possible matches and then optimises over model parameters in order to find a match which best fits for each and every image. The convenient assumption is that only an expression-removing transformation will give a global minimum (or minima), but maybe it is a tad ad hoc, in that sense that it works in practice even without always yielding what it says on the tin. Either way, the ROC curves compare performance of rigid ICP-based algorithm to that of an equivalent, expansive non-rigid approach, which obviously will show the latter doing better; before dealing with the GC set the goal is to produce ROC curves for GIP data. But the matching part is more tricky than it may first appear; there is open admission in the paper that spikes and cruft creep in, so only some hacking around can help in ensuring that valid signal is exclusively preserved.
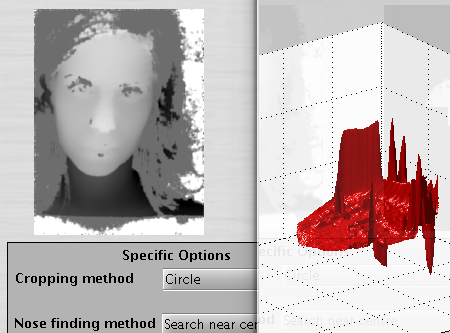
The http://en.wikipedia.org/wiki/Residual_%28numerical_analysis%29residual
images show why: 1) the nose tip detection is crucial to modeling,
otherwise the example must be discarded (standard PCA is not resistant
to outliers); 2) there are many sharp edges at the borders and they
must be removed, otherwise they will dominate the signal in the training
of a model and thus become principal components which we do not want.
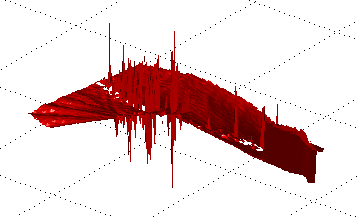
Figure shows a residual as it typically
appears (with spikes) and Figure shows
what happens when the algorithm fails to crop the nose at the right
positions.
At the moment, over 90% of the images in GIP data have the nose (and subsequently the whole structure of the face) detected correctly. The progress made so far is encouraging given that we are able to gradually reproduce a whole Ph.D. project at the capacity of just 50 hours per month (like one week of full-time work). The milestone which is ROC curves can hopefully be reached without much in the form of technical peril.
The recently-composed (and not thoroughly tested yet) code enables the separation between the training and matching phases, which in turn makes future experiments a lot faster (data offloaded to files). Several more experiments were run to test the ground and iron out a few more artefacts like noise. The framework in mind is one that will, as prescribes, morph out expressions using the model that we already build, applying the search to all images in the gallery and then assuming the pair with least dissimilarity to be of the same person.
Untold problems with the modelling phase are not technical issues which are associated with the methods; rather, thy are to do with the nature of the data, especially the way it gets normalised and considered within a particular rigid frame of reference (and faces cannot be explained rigidly when pertinence parts flex and move about). In the interest of progress, we ought to press on and implement all the method, then refine them (later on when time permits). The reason for this is that comparison - namely between PCA and GMDS - is more important than absolute results for the time being. Mian et al. further improved their methods (separate branch of their algorithm) which they then demonstrate in the ROC curves. So, being hopeful that comparable results will be obtained is reasonable, but expecting a rudimentary implementation to fall short is only realistic.
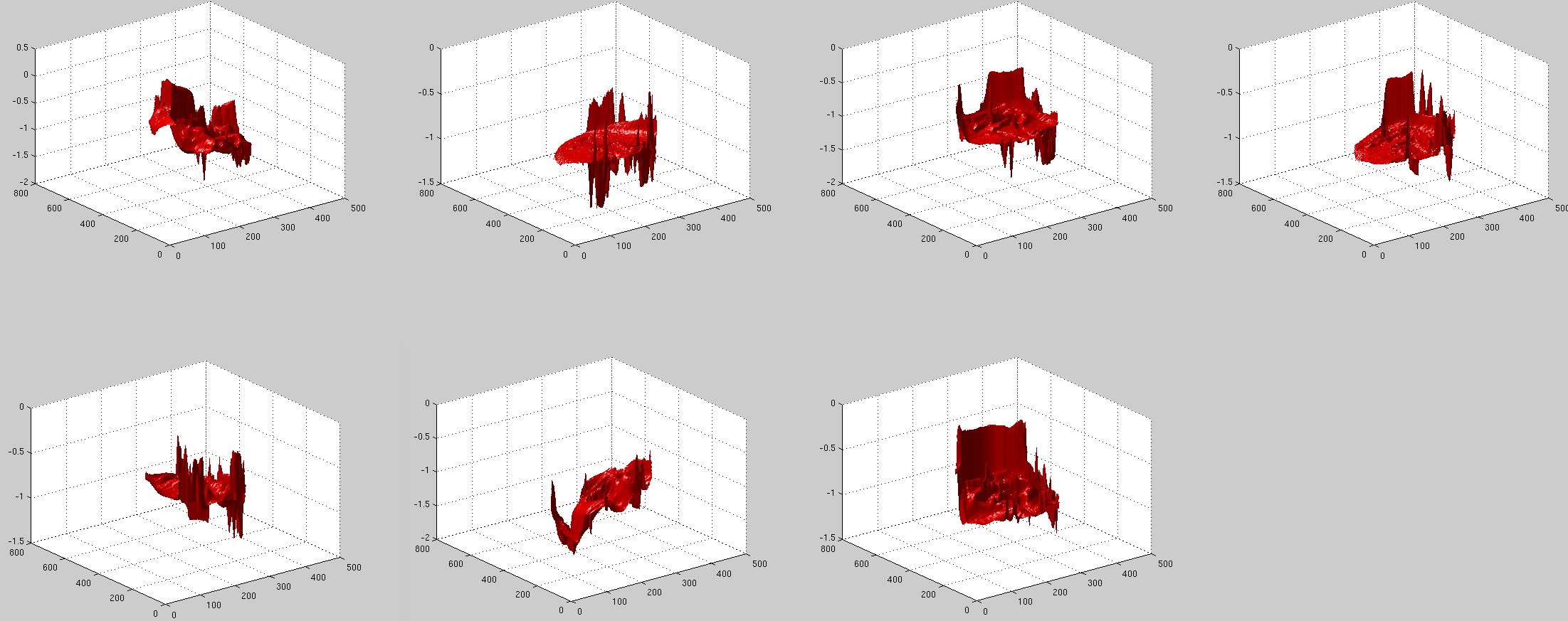
Shown in Figure are some of the
residuals that would give a hard time and demand a lot of testing
to make elegant.