 PDF version of this entire document
PDF version of this entire document
In FRGC 2.0, Experiment 1 and Experiment 2 contain just clusters of 2-D data for training and targets. Partitions of volumetric data are available through Experiment 3, with XMLed links to non-existent files containing the .sfi and .t.sfi suffixes/extensions, even though these are now stored in .abs files (initially the Spring 2003 range), with numbers differing and textures stored in loadable .ppm files (their number is one above the .abs files, they are potentially valuable for future experiments, but irrelevant to the current work and thus discardable). We wrote script files to find and uncompress all the files, then grepped and neditted the XML files to give a list of the files that we want (32 GB of it in total), eventually piping them into MATLAB-style data structures.
Experiment 4 uses a large still training set and there is not much to be found in Experiment 5 and Experiment 6. The 4 experiments from FRGC 1.0 have the same deficiency and therein we find even more of a binary element rather than XML for the BEE framework. So, we are definitely left with just 3 'sub-experiments' which are derived from the third and it ought to be enough as a baseline.
Considerable time was spent trying to find patterns in classification
of facial expressions in the 3-D datasets. Out of 4950 images, about
1000 are used for training and the rest are targets (no separate query
set). This is the largest 3-D face database available out there and
it is said to contain 4007 shape data instances collected from 466
individuals in the gallery (acquired with a Minolta Vivid 900/910
series sensor), the rest being probes from a laser scanner, not an
optical one. This ought to help increase the difficulty of the problem,
e.g. by reducing consistency in the signal. In case it helps, also
given are the manually-marked up coordinates of the noses, eyes, and
chins. Huang et at. [14] show examples taken from
the same subject (top row in Figure ![[*]](/IMG/latex/crossref.png) ) and difficult
cases with holes and occlusion (bottom row). To train a model there
needs to be consistent mapping for separation between neutral and
non-neutral instances. We have that for GIP data, but the set is small
and not identical to what was used in the published paper from Australia.
They might also have expression classification which is needed (a
lot of work to redo, so querying Houston University too might be worthwhile).
) and difficult
cases with holes and occlusion (bottom row). To train a model there
needs to be consistent mapping for separation between neutral and
non-neutral instances. We have that for GIP data, but the set is small
and not identical to what was used in the published paper from Australia.
They might also have expression classification which is needed (a
lot of work to redo, so querying Houston University too might be worthwhile).

|
The exploration and navigation around the existing data ought to have helped remove doubt about existence or absence of necessary data, to remove the possibility of something already being available but hidden away. It does not seem like there is much other than more software tools that are irrelevant to us. This was already clear from the documentation of the FRGC, but looking at each experiment for future insights and understanding of syntactic characteristics was worthwhile.
ROC curves derived in Experiment 3 are conventionally referred to as ROC I, ROC II, and ROC III. These measure the face recognition performance for target and query from the same semester's data collection session, collection in the same year but in two different semesters, and then collection taking place in different years, respectively. The latter represents the most challenging of the three due to all kinds of changes in the environment (e.g. background type, location of face, and intentional lighting variations). Literature survey by search does not bring up many experiments which use these protocols for 3-D, not as strictly described for Experiment 3 anyway. It does appear as though Bennamoun et al. [23] have used this as a yardstick for quite some time. For example, regarding prior work, which was multi-modal, they summarise: We present a fully automatic face recognition algorithm and demonstrate its performance on the FRGC v2.0 data. Our algorithm is multimodal (2D and 3D) and performs hybrid (feature-based and holistic) matching in order to achieve efficiency and robustness to facial expressions. The pose of a 3D face along with its texture is automatically corrected using a novel approach based on a single automatically detected point and the Hotelling transform. A novel 3D Spherical Face Representation (SFR) is used in conjunction with the SIFT descriptor to form a rejection classifier which quickly eliminates a large number of candidate faces at an early stage for efficient recognition in case of large galleries. The remaining faces are then verified using a novel region-based matching approach which is robust to facial expressions. This approach automatically segments the eyes-forehead and the nose regions, which are relatively less sensitive to expressions, and matches them separately using a modified ICP algorithm. The results of all the matching engines are fused at the metric level to achieve higher accuracy.
This paper helps explain some of the otherwise-unexplained bits from the later papers, e.g. nose-finding approach. There are a lot of dependencies among these disparate bits of work from them, which is cumulative in the algorithmic sense.
``Encyclopedia of Biometrics'' (Volume 2), a book by Stan Z. Li and Anil K. Jain, has some more valuable details about the dataset in question and the protocols one must adhere to. A group from the University of Houston describes its work there (first author is Professor Ioannis A. Kakadiaris, Director of the Computational Biomedicine Lab). They also divided the set into neutral and non-neutral, which is curious because such a division is not pre-supplied, which leaves bias to the assessor (not standardised). I will make contact to inquire about it.
Some more manual work may be required for splitting the data as in
the identification case; the dataset needs to be split into a gallery
which contains just one face of the same subject as the probe, which
means that only one correct match would be possible. This can be achieved
by taking the first image of any individual and then treating it as
the gallery part, the rest being probes which need to find/match it.
The cumulative match characteristic curve can then be plotted. For
verification, measuring the fraction of datasets which are returning
positive would also be needed; the false
accept rate (FAR) measures how many of few are classified as positive
given a threshold, e.g. ![]() FAR.
FAR.
The organisers of the Grand Challenge only have this to say about the neutrality of faces (in CVPR '05 [28]): The controlled images were taken in a studio setting, are full frontal facial images taken under two lighting conditions (two or three studio lights) and with two facial expressions (smiling and neutral). The uncontrolled images were taken in varying illumination conditions; e.g., hallways, atria, or outdoors. Each set of uncontrolled images contains two expressions, smiling and neutral.
There is a proper database which allows images to be fetched based on modes, where the attribute 'mode' can have the following values:
mode=Standard
This mode only cares about a target/query pair of recordings if the query recording was taken after the target recording. In these cases it is considered a match if the subject IDs are the same, and a non-match if they are different.
mode=FRGC_2.0_ROC_I
This mode only cares about a target/query pair of recordings if the target and query recordings were taken in the same year, and the query was taken seven or more days after the target. In these cases it is considered a match if the subject ids are the same, and a non-match if they are different.
mode=FRGC_2.0_ROC_II
This mode only cares about a target/query pair of recordings if the query was taken seven or more days after the target, regardless of year. In these cases it is considered a match if the subject ids are the same, and a non-match if they are different.
mode=FRGC_2.0_ROC_III
This mode only cares about a target/query pair of recordings if the query was taken in a later year than the target. In these cases it is considered a match if the subject ids are the same, and a non-match if they are different.
mode=Identity:/home/user/filename.mmx
This is a special mode that simply copies an existing match matrix file to the output file and ignores the target and query signature sets passed in on the command line. The file to copy must be specified after the colon and can be an absolute or relative path. This is the only mode that does not require interfacing with bBase-Lite.There are also 3 masks that are mapping matrices and go along with the ROC ones, but these do not correspond to expressions. Today and tomorrow I will start building models with the data we have, even though for the EDM experiments Bennamoun and his group concede that it is insufficient. They added their own. Figure
shows the sort of images which need to be dealt with.
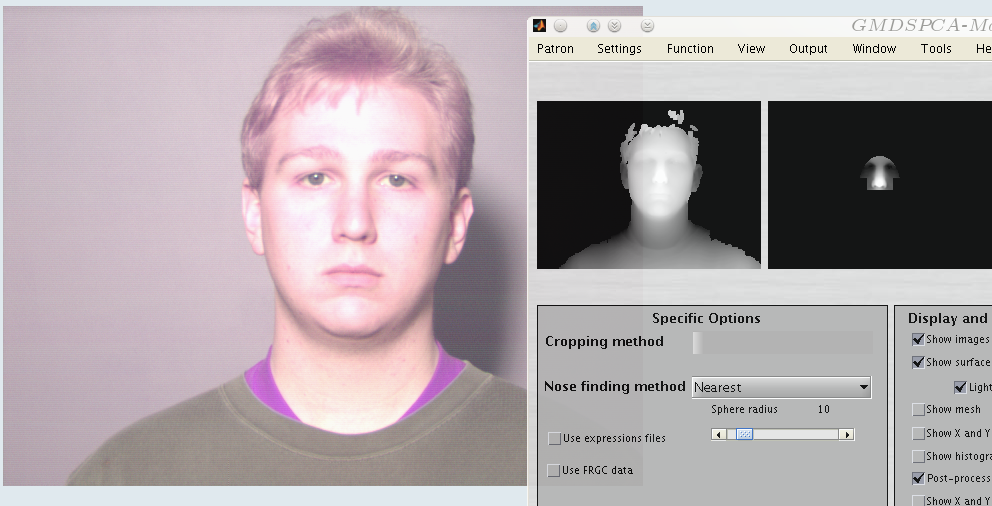
|
If we have most modules from previous papers implemented, there is a baseline fo comparison between existing methods and novel ones. Again, the first that comes in mind is after the ICP refinement of the alignment via GMDS (either with geodesic distances or even Euclidean ones, which is a minor modification to the ICP method). Guy and Dan at the time were converting their ICP into a black box everyone could use (at the time of writing it was unusable).
Currently, we have two ICP implementations (pluggable methods, interfaces
requiring output as ![]() for translation and 3x3 matrix for rotation,
although Euler and Cartesian would work too). Alas, we have not done
any systematic experiments to compare the performance of each. Actually,
I ran some overnight experiments that build a model from the entire
3-D training set (~900 images) after a lot of planning
last night, but the program crashed just one hour into it, so I need
to debug and plan for the next night. It will be useful to see if
computing resources, especially RAM, are sufficient for doing so.
If not, then the program needs to be rearchitected. Then, assuming
that Kakadiaris' or Bennamoun's groups get in touch, we may also need
additional data (Open Access) like neutrality/expression semantics
and datasets for augmentation, as prescribed by them.
for translation and 3x3 matrix for rotation,
although Euler and Cartesian would work too). Alas, we have not done
any systematic experiments to compare the performance of each. Actually,
I ran some overnight experiments that build a model from the entire
3-D training set (~900 images) after a lot of planning
last night, but the program crashed just one hour into it, so I need
to debug and plan for the next night. It will be useful to see if
computing resources, especially RAM, are sufficient for doing so.
If not, then the program needs to be rearchitected. Then, assuming
that Kakadiaris' or Bennamoun's groups get in touch, we may also need
additional data (Open Access) like neutrality/expression semantics
and datasets for augmentation, as prescribed by them.
In Encyclopedia of Biometrics (Volume 2), a book by Stan Z. Li and Anil K. Jain, I saw your group from the University of Houston describing its good work. You divided the set into neutral and non-neutral I would like to inquire about access to such data. I currently work with Prof. Kimmel and we need this type of classification which raw FRGC data does not make available.
Roy Schestowitz 2012-01-08



