Appearance Model Evaluation
February 2005
The Problem
- Given:
- Appearance model
- Training set that generated the model
- Sought:
- Measure of model quality
- Possibilities: specificity, generalisability, etc.
- These method are based on distance
- The question: How can distance be measured?
Distance
- Can articulate distance in terms of parameters
- Intensity differences are problematic
- Wish to account for shape and intensity variation
- It is not clear how to consider both
- They are incommensurate
Requirements
- The measure need to be:
- Easily/quickly computable
- The value will need to be calculated for entire training set
- Complexity is proportional to set size
- Robust to:
- 'Folding' of mappings, e.g. in shuffling (search for match within a fixed window)
- ...
- Other properties:
- Distance from A to C is greater or equal to aggregated distance from A to B and B to C.
- ...
Motivation/Prospects
- The approach will allow to measure faithfullness w.r.t. model
- It is known what the model encapsulates: shape and intensity
- Therefore, the behaviour is known
- Is is based on the synthesis/instantiation
- Model-building procedure is well-understood
Visual Illustrations
- Data lies in space of e.g. parameter, intensity
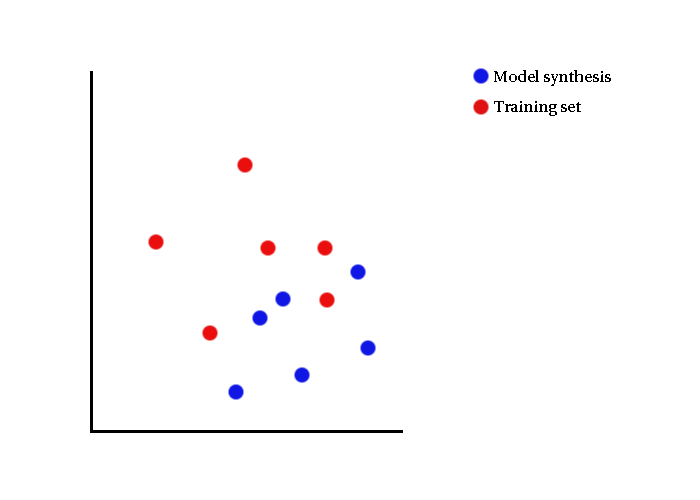
Visual Illustrations
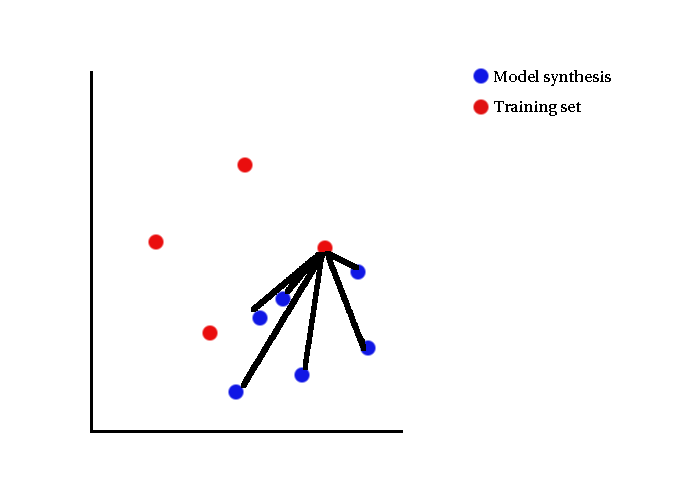
- Each model synthesis is looked at in turn
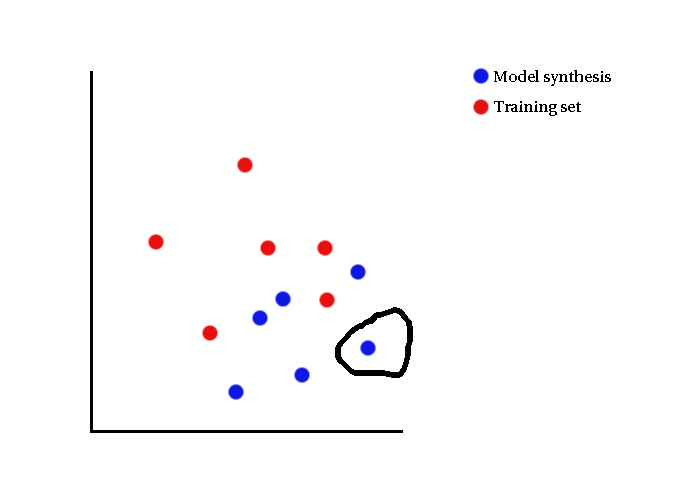
Visual Illustrations
- Distance measured to training set
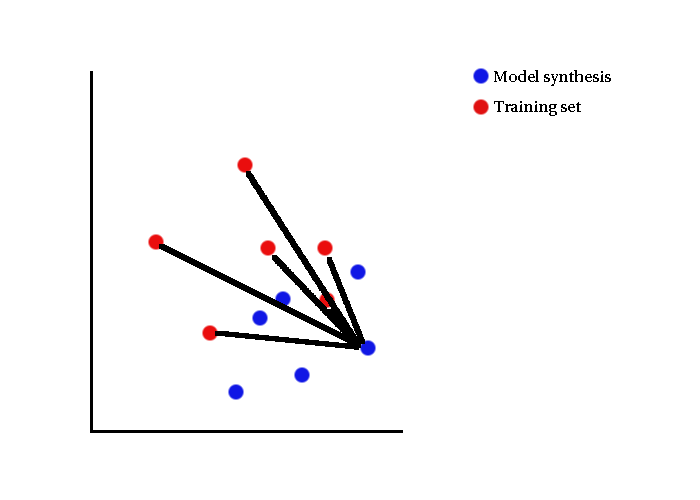
Visual Illustrations
- In specificity, nearest distance is of interest
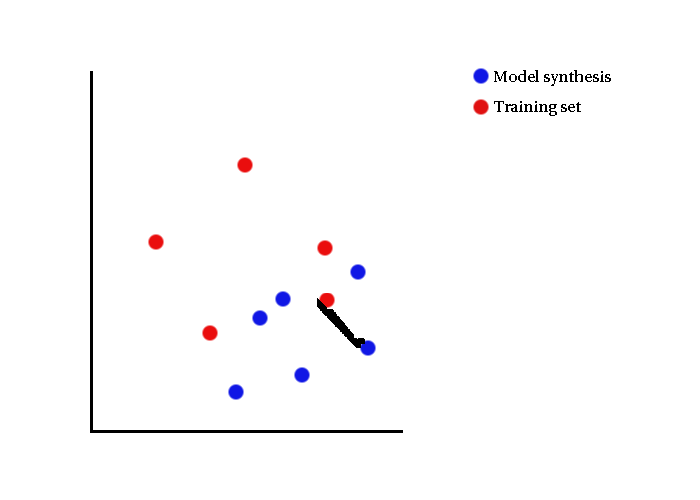
Visual Illustrations
- Generalisability reverses the roles of model syntheses and training set
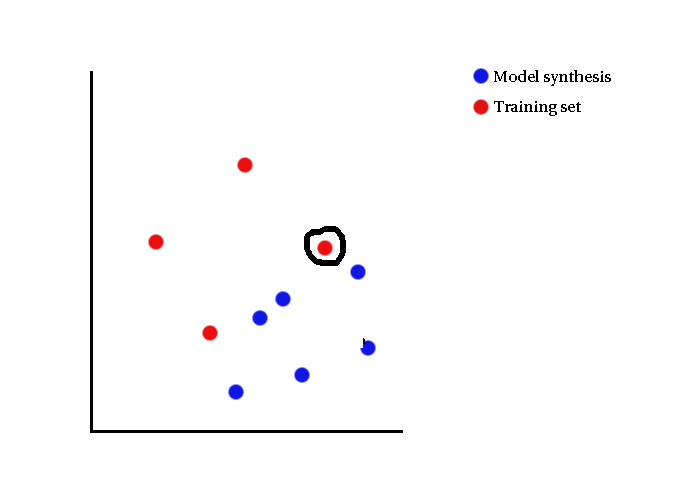
Visual Illustrations
- Does so to ensure the model does not span a large volume in space
Returning to Questions
- What distance should be measured?
- How to treat a finite yet large sets efficiently?
- Some ideas follow...
Visual Illustrations Again
- Let us take a brain and a distorted version of it (whirling filter)
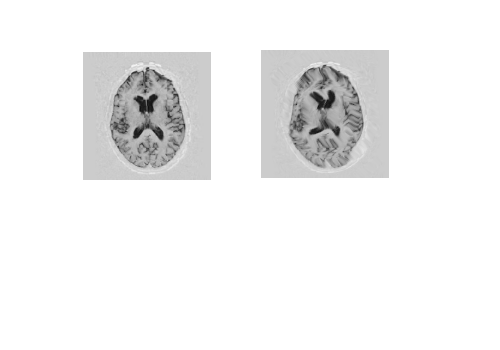
Visual Illustrations Again
- Let us assume one of them is model synthesis
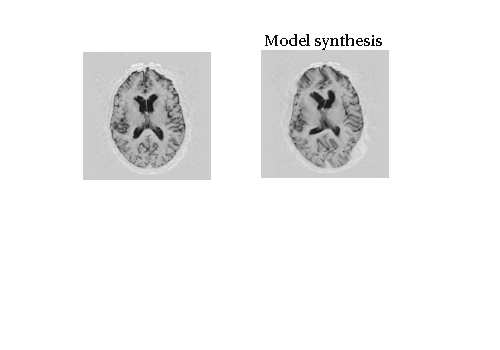
Visual Illustrations Again
- The other one is arbitrarily taken from the training data
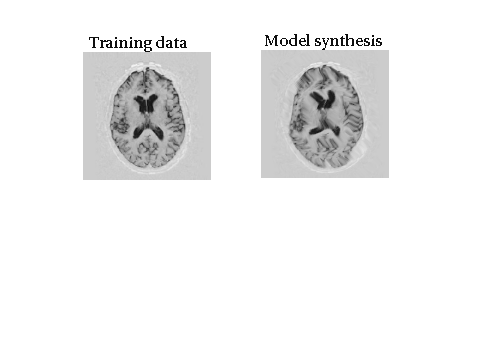
Visual Illustrations Again
- Let us remember that we have a set of training data
Visual Illustrations Again
- The aim is to show that the model is not far apart from the training data (at least some instances)
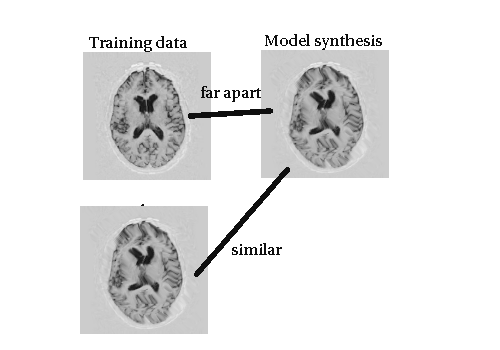
Visual Illustrations Again
- The measure cannot be solely intensity-based
Visual Illustrations Again
- Same brain, different position in space
Explanation
- This is an example of translation inconsistency
- Shape has similar properties
- Example: Brain is wider/narrower
Visual Illustrations of the Example
- The shape change causes great difference in intensities
Visual Illustrations of the Example
- Same brain stretched so must account for shape
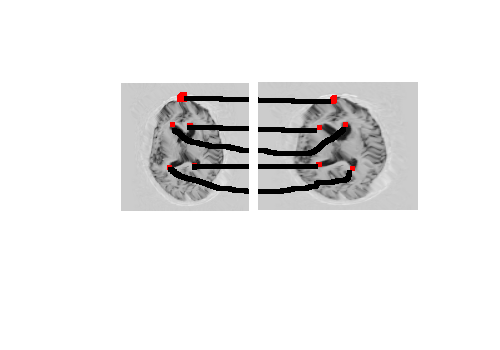
Alternative Way to Measuring Difference
- Try to match point in one image to another within a boundary
Alternative Way to Measuring Difference
- But this can produce awkward mappings
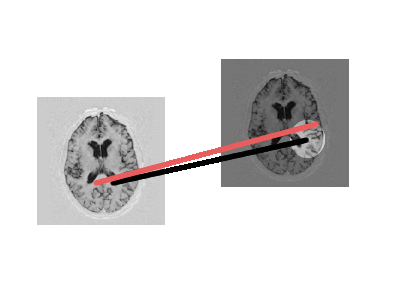
An Idea
- Can measures like MI be of help here?
Discussion
- Using 'general-purpose' similarity measure
- Good for registration
- Will not take advantage of all knowledge
- Does not have proper notion of shape and intensity
- However, quick to compute
More Ideas
- Let us look at the set again
More Ideas
- The distinction between model synthesis and training data instance can be neglected
Discussion Again
- All that is needed is a metric of distance
- Takes only 2 images (or volumes) at a given time
- Distance relates to intensity and shape
- Care for efficiency
Simplified View
- Look at only two instances
Simplified View
- Model synthesis holds extra information
What is Required
- Showing that model describes instances fairly thoroughly
- Model does not describe illegal instances
- Specificity and generalisability do this
- Specificity 'handles' the former condition
- Generalisability 'handles' the latter
Several Contraints
- The metric needs to be robust to awkward instances
- Example #1: Void image
- Example #2: Reversed (flipped/mirrored) image
- Example #3: Strange shape variation in uniform areas like background
Returning to Simplified View
- What if subsets of training sets taken?

Returning to Simplified View
- Construct model of subsets and perform model comparisons?
Another Thought
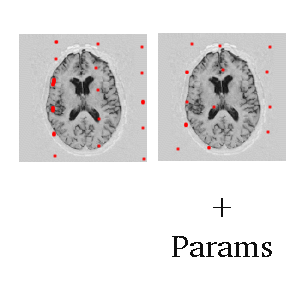
Another Thought
- What if the images are taken
Another Thought
- Points of correspondence to be used
Another Thought
- Triangulate and treat as features
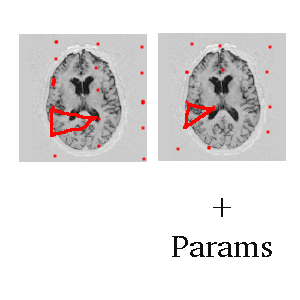
Another Thought
Explanation of the Ideas
- Taking intensity of points of correspondence (control nodes) is unreliable
- Not enough nodes in practice
- Sampling along them might not give good matching locally, pixel-to-pixel
- By modelling, there is a more tolerant measure
Other Ideas to Ponder About
- Once similarity is obtained...
- ...how does one use it to measure quality of entire model
- Most reasonable to look at the problem in terms of representation in space
- Reliability and efficiency have trade-offs