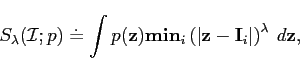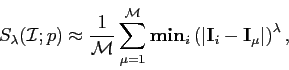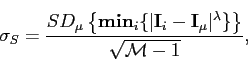PDF version of this entire document
PDF version of this entire document
Consider first the training data for the model, that is, the set of images to which NRR is applied. Without loss of generality, each training image can be treated as a single point in an ![]() -dimensional image space. A statistical model is then a probability density function (pdf)
-dimensional image space. A statistical model is then a probability density function (pdf) ![]() defined on this space.
defined on this space.
To be specific, let
![]() denote the
denote the ![]() images of the training set when considered as points in image space. Let
images of the training set when considered as points in image space. Let ![]() be the probability density function of the model.
be the probability density function of the model.
A quantitative measure of the specificity ![]() of the model is defined, wrt the training set
of the model is defined, wrt the training set
![]() as follows:
as follows:
![[*]](/IMG/latex/crossref.png) , diagrammatic examples of models with differing specificity are given.
, diagrammatic examples of models with differing specificity are given.
The integral in equation can be approximated using a Monte-Carlo method. A large random set of images
![]() is generated, having the same distribution as the model pdf
is generated, having the same distribution as the model pdf ![]() . The estimate of the specificity () is:
. The estimate of the specificity () is:
below.
It is worth adding that while more specific models will be close to the training data, complete separation between the two groups of images (training and synthetic) ensures there is no bias.
Roy Schestowitz 2010-04-05