





Tuesday, April 25th, 2006, 2:24 am
Detection of Fake Content
 Filed under:
Filed under:

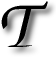 HERE is a growing interest in snatching of Web traffic from search engines. A notorious method for achieving this is by large mass of useless and re-used content. This is backed by many inbound links, which are most commonly accumulated by spamming of other Web sites. The overall outcome of this is degradation in the quality of publication on the Web. Likewise in science (sometimes at least!).
HERE is a growing interest in snatching of Web traffic from search engines. A notorious method for achieving this is by large mass of useless and re-used content. This is backed by many inbound links, which are most commonly accumulated by spamming of other Web sites. The overall outcome of this is degradation in the quality of publication on the Web. Likewise in science (sometimes at least!).
There are real technical papers and fake ones as well. SCIGen was at one point utilised to output randomly-generated publications, one of which was actually accepted to be presented at a conference.
Finally, there is a new tool,which claims to be able to discern real technical papers from fake ones.
Authors of bogus technical articles beware. A team of researchers at the Indiana University School of Informatics has designed a tool that distinguishes between real and fake papers.
It’s called the Inauthentic Paper Detector — one of the first of its kind anywhere — and it uses compression to determine whether technical texts are generated by man or machine.
