 PDF version of this document
PDF version of this document



In order to measure the quality of a model, a measure was
devised which reflects on its occupancy in a high-dimensional space.
The method measures how well one cloud of points fits another. One
cloud comprises the training set of the model whereas the other accommodates
many model syntheses. A similar approach was used to evaluate shape
models![[*]](/IMG/latex/footnote.png) , thereby building optimal models of shape automatically.
, thereby building optimal models of shape automatically.
The measures are based on distances between examples in two groups of instances. The first of these measures, namely specificity, is intended to discover how well a model describes its training set. The other - generalisation ability, indicates how closely the training set fits within the model. To represent the model, many synthetic instances need to be generated from it. The safe assumption is that a large enough number of instances is capable of approximating the model's behaviour.
![\includegraphics[%
scale=0.35]{EPS/model-horizontal.eps}](img4.png)
Fig. 3. The model evaluation framework. Each image in the training set is compared against all model-generated syntheses
Shuffle distance is defined to be the minimum value for every pixel with respect to a group of pixels in its vicinity in a second image (see Fig. 4).
![\includegraphics[%
scale=0.35]{EPS/shuffle_deformation.eps}](img5.png)
Fig. XXX. Varying number of warps are applied to the training set of a model whose specificity is then evaluated using Euclidean distance and shuffle distance with varying window sizes.
![\includegraphics[%
scale=0.4]{EPS/shuffle.eps}](img6.png)
![\includegraphics[%
scale=0.29]{EPS/shuffle5x5_power1.eps}](img7.png)
Fig. 4. Illustrating the essence Fig. 5. An example of the shuffle
of a shuffle distance image distance image when applied to two brains
To calculate 'distance' between two images, the me an intensity of the resulting shuffle distance image should be taken. This simple idea has proven to be fast, as well as powerful.

Let
![]() be a large image set
which has been generated from the model and has the same distribution
as the model. The distance between two images is described by
be a large image set
which has been generated from the model and has the same distribution
as the model. The distance between two images is described by ![]() and this allows us to define:
and this allows us to define:
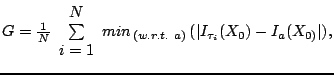
 .
.
Algorithmically, a method can then be devised for evaluating models. It is based on generalisation ability and specificity and it consists of the following steps: