PDF version of this entire document
PDF version of this entire document
With smoothing made better (covers a wider area in true 2-D) and the
resolution increased somewhat, results so far show the threshold just
approached by two images. It is premature to draw conclusion and too
early to suggest that separability has been degraded/improved, but
the good news is that GMDS has not failed in a major way, not for
correct pairs anyway. This whole process could still use some tweaking
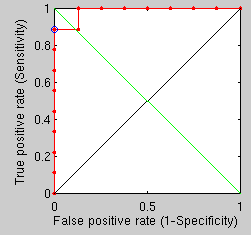
and there are several ways remaining for improvement. Figure ![[*]](/IMG/latex/crossref.png) shows this graphically.
shows this graphically.
The results based on first few iterations show just one minor error,
as show in Figure
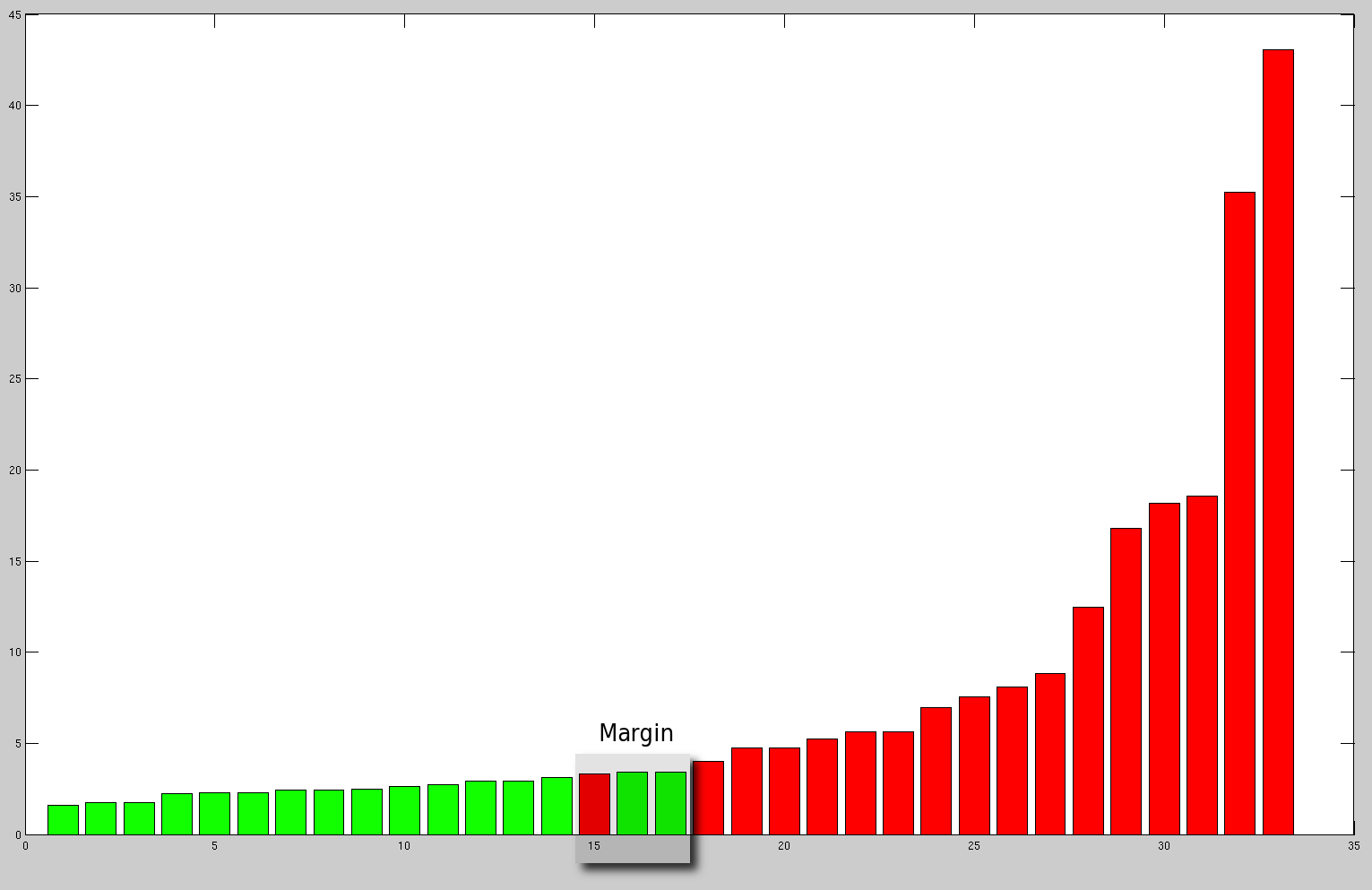
Basing the next experiment on the situations where detection merit/recognition
value is on the margin (around 3 in this case), here are the 3 problematic
image pairs (see Figure ), which seem
to suggest either a weakness in GMDS as a similarity measure or a
gap in implementation. The good news is, by upping the resolution,
cases of incompatible topology have been eliminated, at least for
the test set in this case (about 30 pairs of images).
The false positive seems strange. GMDS is obviously not optimal, so we need to understand the sources of the these problems and try to program them out.
Interestingly enough, all the numbers are repeatable and reproducible
despite the stochastic element and contrary to prior cases (coarse
resolution). They stay the same across run, with a 3-decimal-point
accuracy. In Figure are the three pairs shown
previously, in context.
It is hard to understand then how the false positive came to be. The geometries look substantially different. Dealing with this problematic image in isolation, the relative values of GMDS (relative to other of its kind) were studied to better understand when and why they diverge to the point where GMDS matches quite well faces that are from different people (and inherently dissimilar). At 3600 vertices it enters the margin like no other pair does. At 2500 this problem persists and at 1000 this problem is gone (the score is well within the true negatives territory). But at 600 it becomes a tad problematic again.
With smoothing and other parameters kept invariable, it should be possible to run these experiments at multiple scales and then learn by observation how to later conduct an uncontrolled, unsupervised and blind experiment where more than just one single GMDS operation is used to assess similarity. Another possibility would be to 'hybridise' methods, e.g. use a simpler method of comparing pairs in conjunction with GMDS, or as a sort of regularisation term in a more compound objective function (maybe normalised as well).
Roy Schestowitz 2012-01-08