PDF version of this entire document
PDF version of this entire document




F ollowing a systematic process which looks at two analogous approaches was originally sought for the studying of PCA and GMDS, but we moved on well beyond that. This section embodies some results from early work.
The aim is to obtain the same ROC curves as reported in the IJCV paper so that we have a baseline for comparison. Once this goal is obtained, the next goal would be replacing the ICP/PCA with GMDS, Or maybe even refine the alignment with GMDS and hope for better recognition rates. When it is time to run GMDS there ought to be efficient implementation to work with.
In order to get the required results it is worth outlining exactly what is missing before getting the ROC curves of Mian et al. As the implementation stands at this stage, it sometimes misidentifies the nose tip, which is very unhelpful if it then feeds PCA (and obviously pollutes the signal). We could tackle this maybe by selecting a large subsets of images which we know can be handled in an acceptable fashion; otherwise it's back to going around in circles trying to tweak for particular cases and then botching the others. This is the most frustrating part of this project, and clearly it became a distraction because it's the part which is not novel and we mustn't care about all that much. This took more time than the whole GUI.
As filling holes and smoothing if a source of difficulty we have reused some simple denoising/hole filling filter.
Regarding nose identification, if we take a generic nose (template) and try to ICP it to the estimated location, then there is room for improvement. That this is more or less what we were trying to achieve, but if we take a couple of such template noses, then there is also improved robustness, so that is definitely an idea worth implementing. Provided that one can remove all the points associated with the background, the cloudpoint we try to do fitting with should suit the template's surface (or one of several candidate surfaces corresponding to templates). In fact, we could take such a generic nose with high resolution (cloud of points) and lower resolution as we depart from a generic mask.Multi-scale and search window might be needed because in the database provided by the Grand Challenge project coordinates there are some odd cases where the imaged person is somewhere at the side and very much away from the aperture. If it is intentional, it begs to test one's ability to locate faces, not just recognise them.
Alternatively, we could train a Viola-Jones like detector for the
tip of the nose (with enough support) that would work on the shading
image created by, for example, the shading image. It would then serve
as initial conditions for the above ICP trick. We ended up implementing
new means of reliably finding the nose in grainy images. ICP should
be resistant to localised noise and phantoms that may resemble a nose,
assuming that the background can be removed in a consistent fashion.
This in its own right is an interesting approach. The accompanying
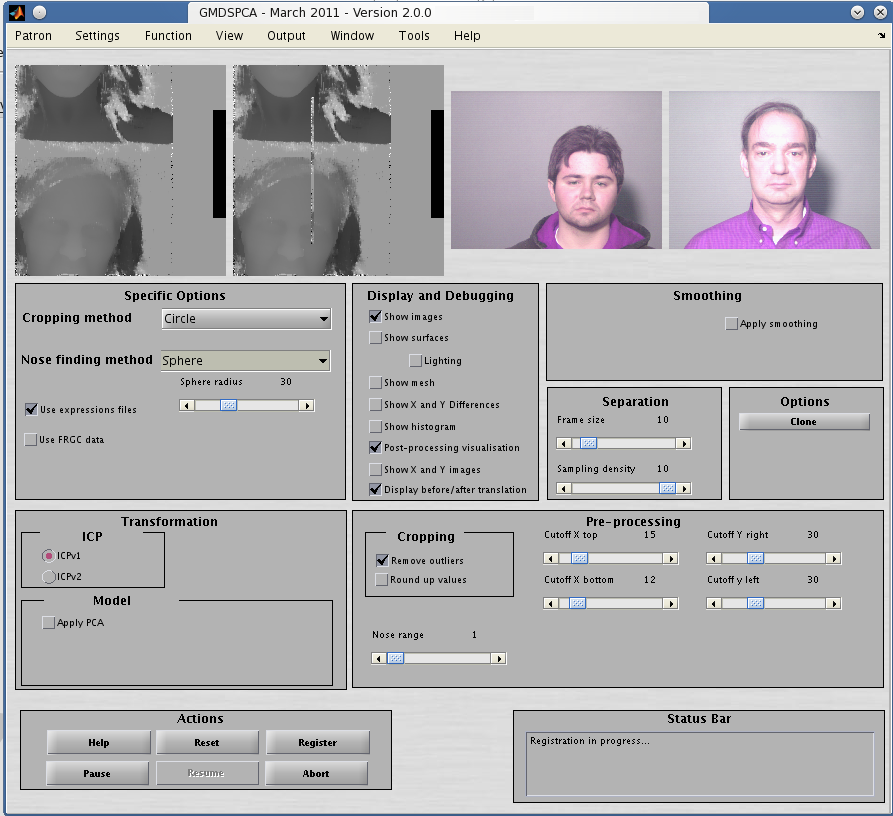
image shows the GUI with the axes displaying post-filtering data ![[*]](/IMG/latex/crossref.png) (can
also show it as a surface given the tickboxes). Aligning video frames
is a separate challenge that needs tackling.
(can
also show it as a surface given the tickboxes). Aligning video frames
is a separate challenge that needs tackling.
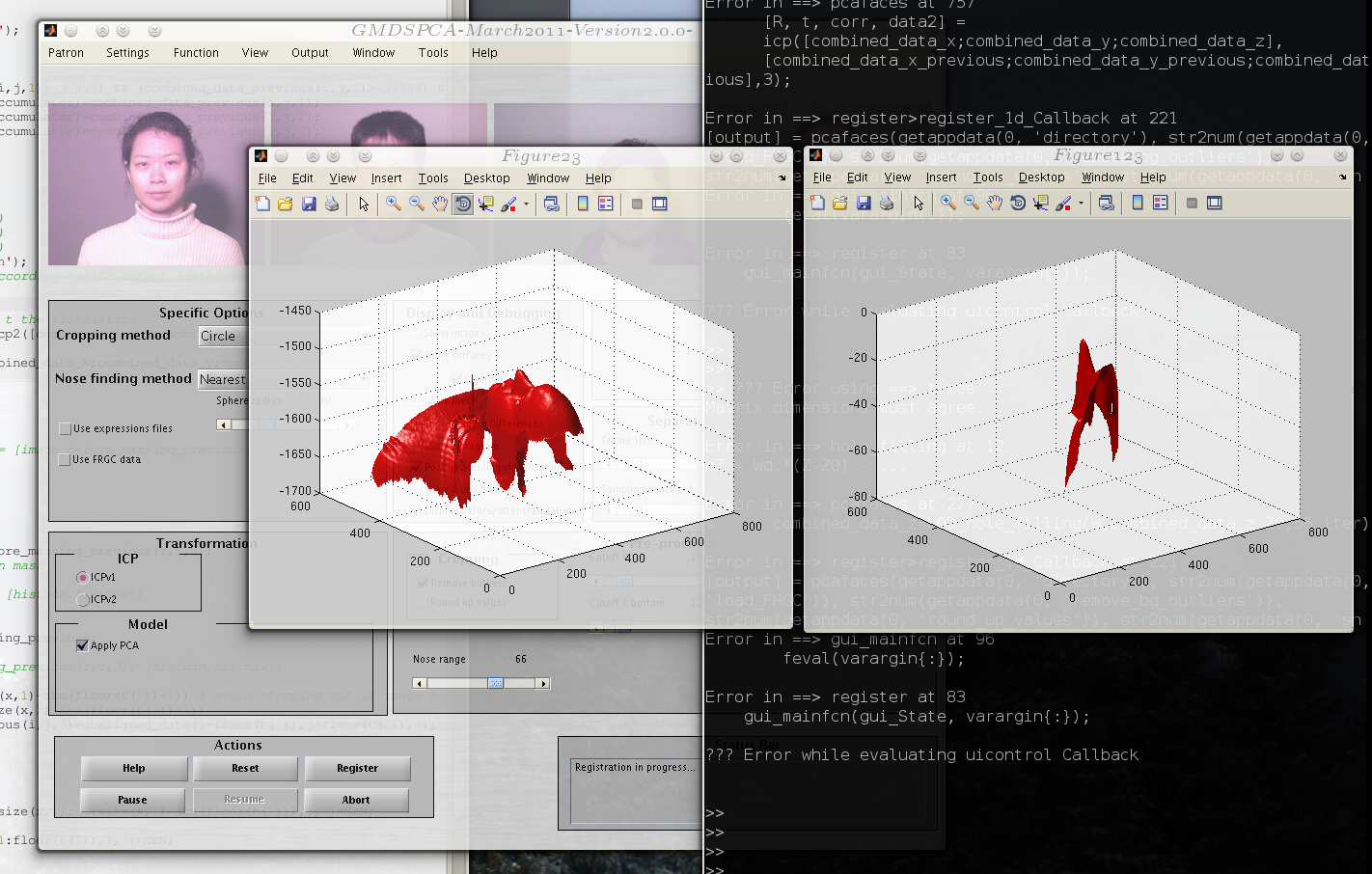
ICP-based nose tip detection is implemented with various options, but the results thus far are unsatisfactory because the suggested alignments are incorrect. If smaller regions are chosen for the template (avoiding the mandibles and choosing just the nose region), more or less the same type of results are arrived at. http://en.wikipedia.org/wiki/Viola-Jones_object_detection_frameworkViola's method seems interesting but unavailable22, so for the time being, further refining an ICP fit is worth exploring. In addition, I mailed Yaron to ask about frame calibration.
While digesting and processing the frames of the video sequences one at the time, noise gets removed using some filters and the face can then be seen more clearly. There is additional difficulty, however, especially when it comes to dealing with the lack of frame calibration, meaning that when a frame other than the first is opened there is basically a dividing area between two frames (or complementary parts of the same frame), so additional code which gives one clear picture is required. It was worthwhile checking if someone already written such code, but it looks like an offset, so in subsequent we have an offset in writing to the buffer. If we try to read each frame separately and display it in MATLAB, there is still an odd effect. By using a function call like readGipFile(expressions_fileName, image_n) this behaviour is reproducible with, e.g.:
displayRaw_SingleFromVideo
taking paramaters:
fileName = '~/Facial-Expressions-Recognition/Smile.v3r'; frameToView = 8;
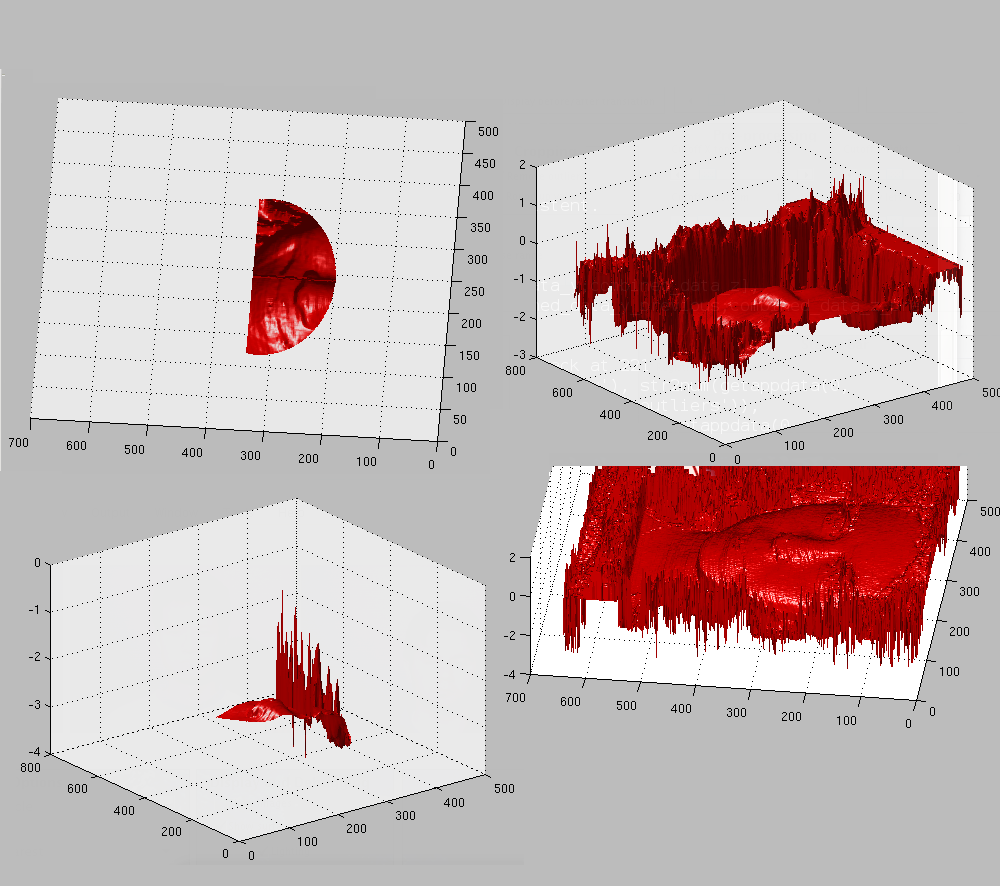
There is a thick line in the middle of the face where cloudpoints do not appear at all23.
As for frame being less than calibrated, it turns out that the file
loaders need some special offset for any frame other than the first
in the sequence. Once issues such as this are out of the way, it should
be possible to handle the interesting parts of the experiments. This
data type in general, unlike the typical one that is easy to deal
with , is very noisy and the face not so trivial
to identify with great certainty .
Here is an image showing how we presently handle GC faces... almost always well enough. GIP data (typo in filename) is more complicated. We correspond about that. Having tried ICP and Viola's (et al.) method, there was not much progress because the ICP one needs decent initialisation and the latter just finds lots of faces all over the place, or none, depending on how it is used. We can try to train it on noses rather than whole faces (which in turn give good estimates of nose location using simple measurements). The problem with that is, the cruft all over the image space - and especially the sides - sometimes resembled small noses. Suffice to say, looking at the images, getting an initial estimate of where the nose typically is, then initialising there would be easy, but it would not generalise to other datasets; ad hoc methods are assumed to be another realm altogether - one where we use tricks to get things working on particular datasets (convenience/pragmatism) rather than develop robust computational methods (principled approach). It's tempting to just embrace the former approach, at least for now. Explaining and reasoning along the lines of, we look for a nose somewhere in the middle is just not compelling enough (sloppy even), not as much as leveraging of Paul Viola's recent work. These issues something crop up in peer reviews, so sometimes it's better off done right in the first place and not later on, some time in the foreseeable future when exceptions creep in. The same goes for hacking-like development where the code works but becomes unmaintainable and unusable to anyone but its author/s. People typically learn this the hard way, through arduous experiences and frustration. The GUI now has ICP and Viola-Jones as possible methods in the drop-down menu. We shall see what else we can find/do...
The program is centimeter-aware and also pixel-aware, so different measures are taken into consideration, e.g. when looping through pixels/cloudpoints and when performing a physical measurement (nose to forehead for instance).
A fifth nose-finding method is now implemented and it takes a small range within which to find objects resembling a nose (using the method from Mian's group, but limiting the search window). Dealing with frame offsets is another matter and working around it not at API level would be unwise. We lack an expressions-neutral GIP dataset, too. Meanwhile we press on with ICP/PCA code.
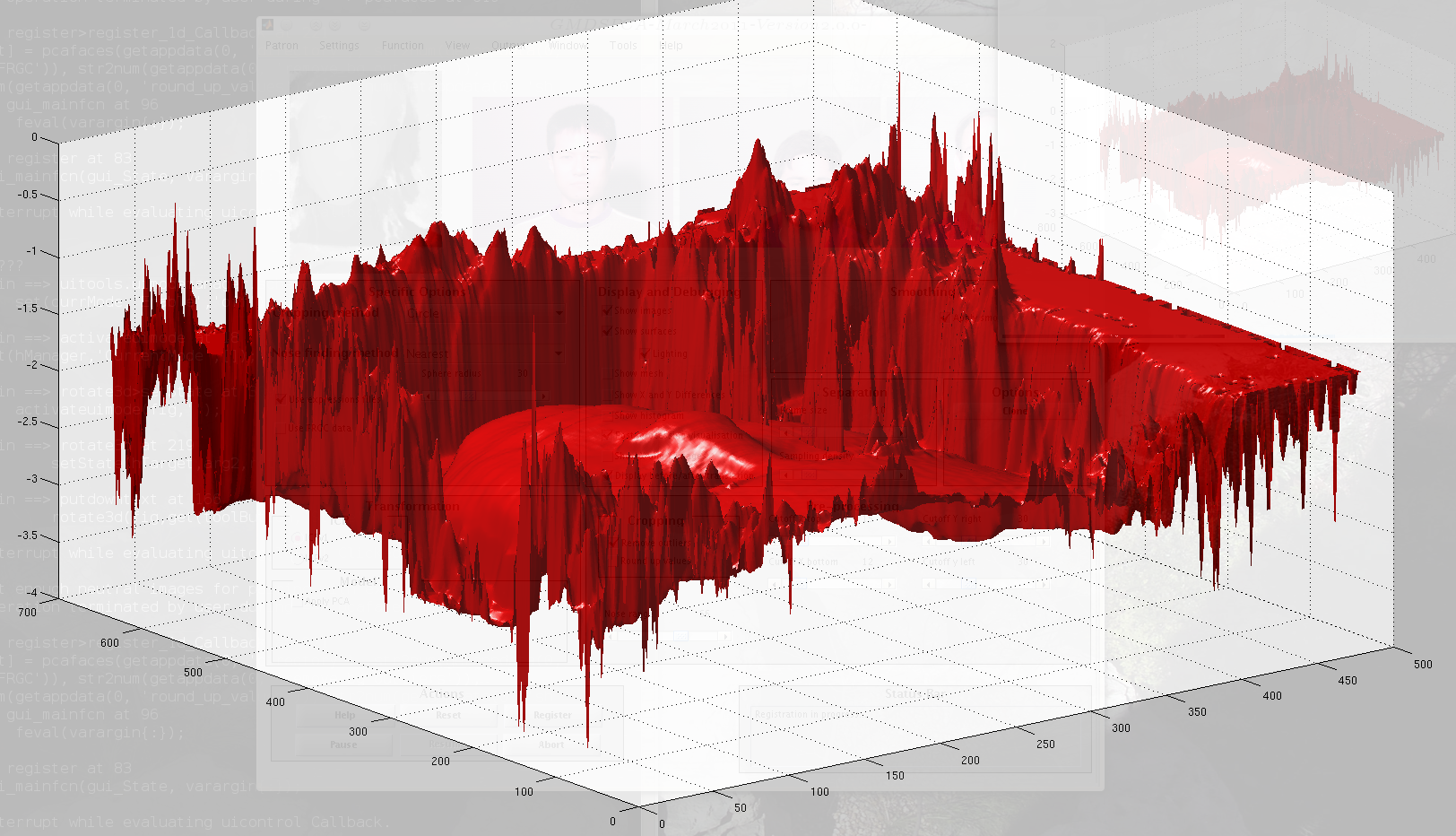
Here are some more images which are examples of
our 3-D registration, based on the matching of two cropped faces that
are centred wrt the same axes. Rather than display just the cropped
cloudpoints after registration, shown here are the difference images
of the entire face surface before and after registration. This is
just a sample of several such images which are generated with robust
cropping having been applied (all hits, no misses) to mostly expression-neutral
scans selected at random.
The plan was, at this stage, to see some ROC curves. We will get to that later.
OK, I will start running large experiments, but one might warn in advance that the expressions dataset has no neutrals in it. I will make something rudimentary to serve as a baseline and notes will be expanded to keep track of progress.
An implementation of offset correction will be required for GIP data
(See (Figure ). Otherwise, as the images
show (Figure and Figure ), the
face images which contain a lot of noise and move up/down depending
on the frame, leading to mis-location of the nose tip marker. A way
of visualising the shape residuals is now implemented too.
|
I ended up writing some code to annul the effect of frames being divided upon themselves. It was reasonable to be surprised that code in GIP examples did not already have this, so suggested for it to go upstream, too.
Acknowledgements: the project was funded by the http://erc.europa.eu/European Research Council.