- ... Schestowitz1
- Dr. Roy S. Schestowitz holds a Ph.D. in Medical Biophysics, which
he received from the Victoria University of Manchester where he specialised
in statistical analysis of shape and intensity characterising soft
tissue. He also worked on a novel approach for assessing dissimilarity
using combined models of 2-D faces and 3-D brain data (notably MRI)
before working on cardiac MRI for real-time tracking purposes.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...
progress2
- A lot of material in textual form was being assembled throughout development,
including technical explanations and explanations in the form of visual
elements that demonstrate textual descriptions (e.g. tables, images,
screenshots).
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... job3
- Humans are used to recognising faces by texture and crude stereo vision,
not full 3-D.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... parallelisation4
- In his IJCV paper, Bronstein stresses that ``[t]he inner geodesic
distances were computed using an efficient parallel version of FMM
optimized for the Intel SSE2 architecture (using our implementation,
a matrix of distances of size 25002500 can be computed
in about 1.5 seconds on a PC workstation).''
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... index5
- The challenge of searching for matches in large databases is a complex
problem in itself. It can use a coarse-to-fine (multi-scale) approach
or signatures that act somewhat like hashing.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... components6
- There are different possible colour schemes, but they need not have
any effect on principles of sampling intensities.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... shape7
- Warps can be applied using a strategy borrowed from graphics. In all
experiments described in this thesis this was achieved by a triangulated
mesh generated from the landmark points and barycentric coordinates
to mesh the intersections put in vector
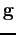 .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...8
- The letter
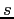 stands for shape, as by default this matrix
scales the shape parameters only. It gives logically equivalent results
to these of applying the factor
stands for shape, as by default this matrix
scales the shape parameters only. It gives logically equivalent results
to these of applying the factor
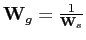 to intensities.
to intensities.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... model9
- There is finally code in place for plotting the http://en.wikipedia.org/wiki/Pareto_distributionPareto distribution
of the built model, which can be used to show how much of the variation
each mode accounts for and how this ratio degrades. The problem is,
without resolving difficulties of fully automatic face cropping and
then applying that to a large set, the data will just be noisy and
the modes rather uninteresting. For small dataset (run for testing
purposes) there are hardly any modes at all, in lieu with the size
of the sampled set fed into PCA.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... pixels10
- The common computer vision approach of locating and segmenting image
parts, e.g. for partial similarity on a per-part basis with scoring,
with or without weighting based on statistical/topological/irregular/anatomical
significance - that which can more uniquely identify in image within
a group or even externally, as belonging to one group of images and
not other groups.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... FRGC11
- We do vectorise the code as much as possible, for the sake of speed.
Alas, it is still cumbersome and slow.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... dataset12
- find | grep .abs | wc allows us to count and handle all images
by taking them one by one and then just handling them one single image
at the time. There are many in the current collection, 4950 to be
precise; all of them are compressed, as find | grep .abs.gz
| wc helps reveal. To get a list of the 3-D faces, one can run, e.g.
find | grep .abs.gz | awk '/{print $1}' 1>~/files_list.txt,
which yields something like the following: ``./nd1/Spring2003range/04334d218.abs.gz;
./nd1/Spring2003range/04419d182.abs.gz; [...] ./nd1/Spring2004range/04936d102.abs''.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... Australia13
- Faisal R. Al-Osaimi completed his degree in 2010. He was Mian's first
Ph.D. student.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... alignment14
- This is very much needed for landmark points and thus correspondences
to be identified, otherwise we model nonsensical examples.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... swapped15
- In one of their original papers, the authors' abstract states that
they present an ''algebro-geometric solution to the problem of segmenting
an unknown number of subspaces of unknown and varying dimensions from
sample data points. We represent the subspaces with a set of homogeneous
polynomials whose degree is the number of subspaces and whose derivatives
at a data point give normal vectors to the subspace passing through
the point. When the number of subspaces is known, we show that these
polynomials can be estimated linearly from data; hence, subspace segmentation
is reduced to classifying one point per subspace. We select these
points optimally from the data set by minimizing certain distance
function, thus dealing automatically with moderate noise in the data.
A basis for the complement of each subspace is then recovered by applying
standard PCA to the collection of derivatives (normal vectors). Extensions
of GPCA that deal with data in a highdimensional space and with an
unknown number of subspaces are also presented.``
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... now16
- In page 12 of the IJCV paper they state that about
2% of the probe scans were misdetected due to these
errors that we have, but they have had more time to work on these.
It's the less finely documented part of their work, which presents
itself as trivial by hiding the creases.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... benchmark17
- To grossly define a classification benchmark in this context, it ought
to be possible to model different 'families' of variation (such as
anger, fear, etc.) and then classify an unseen image based on model
fit. It would seem quite novel and it probably ought to work.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... translation18
- Mian-style objective function needed for comparisons, with rotation/clipping
addressed as part of him transformation needs fixing.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... time19
- It ought to be a simple problem to fix as it is very clear based on
the score whenever bad detection has occurred, the score being an
order of magnitude higher than expected.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... Web20
- To assess everything more formally, the http://en.wikipedia.org/wiki/Face_Recognition_Vendor_TestFace Recognition Vendor Test
was later on used for reference.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... cases21
- To accentuate discriminative properties, e.g. for comparative purposes
and debugging.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... unavailable22
- Although implemented in http://en.wikipedia.org/wiki/OpenCVOpenCV
which means we may have to code it from scratch, at least if moving
in this direction. Upon closer inspection, there is an implementation
we can reuse over at http://www.mathworks.com/matlabcentral/fileexchange/29437-viola-jones-object-detectionMATLAB Central.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ... all23
- Among the available functions there are displayFiltered_Single.m,
displayFiltered_SingleFromVideo.m, displayRaw_Single.m,
displayRaw_SingleFromVideo.m, readFrameProperties.m,
readGipFile.m, and readGipFileHeader.m.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
 PDF version of this entire document
PDF version of this entire document