PDF version of this entire document
PDF version of this entire document
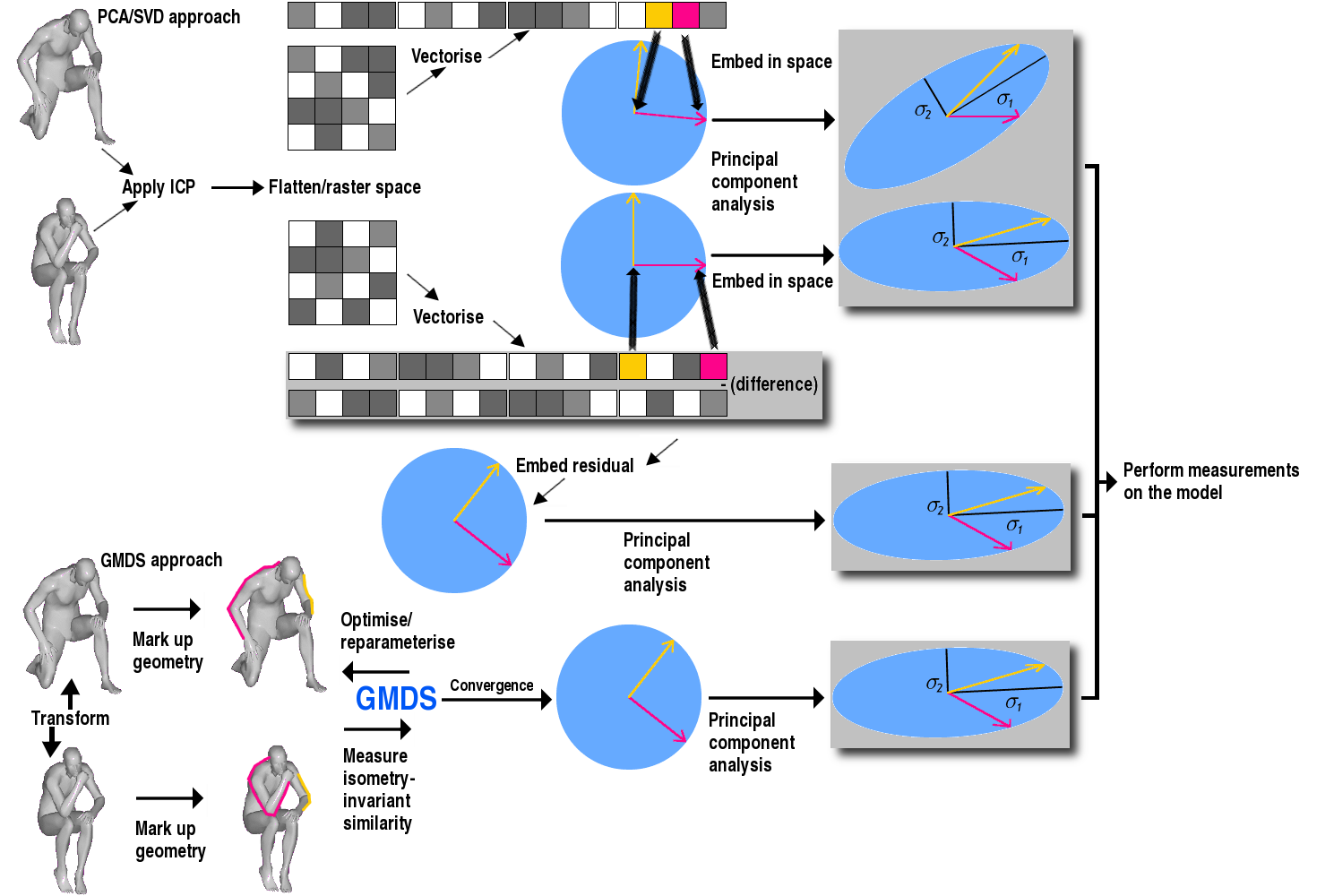
The modeling part of the method is loosely defined for a good reason. We wish to compare different paradigms for attaining a model. We can conceive a robust-PCA that would lead to sparse representation and eventually GMDS. It is currently being made as efficient as possible (with means of hardware acceleration too) and there will hopefully be mature GMDS-based software tools to work with quite soon, with prospects of replacing PCA with something less generic and better optimised for purpose.
PCA and GMDS have some clear similarities at some lower level. In MDS and GMDS we treat shapes in a metric space and assume that shape similarity can be reliably measured in terms of the distance between metric spaces. Dimensions correspond to variation along geodesic lines of significance, which in a sense is similar to a landmark point (coordinate) or a texture that can be handled with dimensionality reduction in PCA with all its variants/enhancements. The geodesic measure is more expressive and suitable for surfaces and some of the associated methods that require classification. The invariance tolerance that an isometry-preserving warp/deformation inflicts upon a shape is similar to the restraint in bending of, e.g. anatomy, as judged by PCA automatically. The topology problem can exist also in PCA, especially if the sampling of observations gets automated. There are factors to be considered such as the nature of the metric which determines the sort of transformations to which topology is not an issue. It also generally depends on the shapes dealt with. Some may need additional information to resolve ambiguities. GMDS problems can be solved by optimisation to help find minimal distances for a group of different metric/dimensions, just as PCA identifies dimensions along which data can be flattened and later reconstructed, through the eigenvectors that correspond to those lines/planes.
Shape descriptors are defined such that they can reconstruct a whole class of shapes that are canonical forms and if they are defined at every point on the shape, then they are too dense to provide something specific (just too generic). It is therefore necessary, just like with landmark points for PCA sampling, to pick anatomically or statistically meaningful parts, perhaps assigning weights to them instead in order to limit their influence on the model (like some PCA variants do, as does GMDS). For the measures to be insensitive to topology errors, all sorts of ad hoc methods can be used, but some require understanding the general shape or have a broader class of that shape to compare to and learn from.
The duality of this problem can be expressed visually as well as with
equations, to an extent. It would be useful if we produced figures,
which are probably better off prepared for use later on (explanatory
purposes). It would be beneficial to do so as we envision sequence
of events as PCA/singular value decomposition (SVD) generic classification
followed by GMDS robust PCA for refinement. To conceptualise this
description accurately, it might look like Figure ![[*]](/IMG/latex/crossref.png) .
.
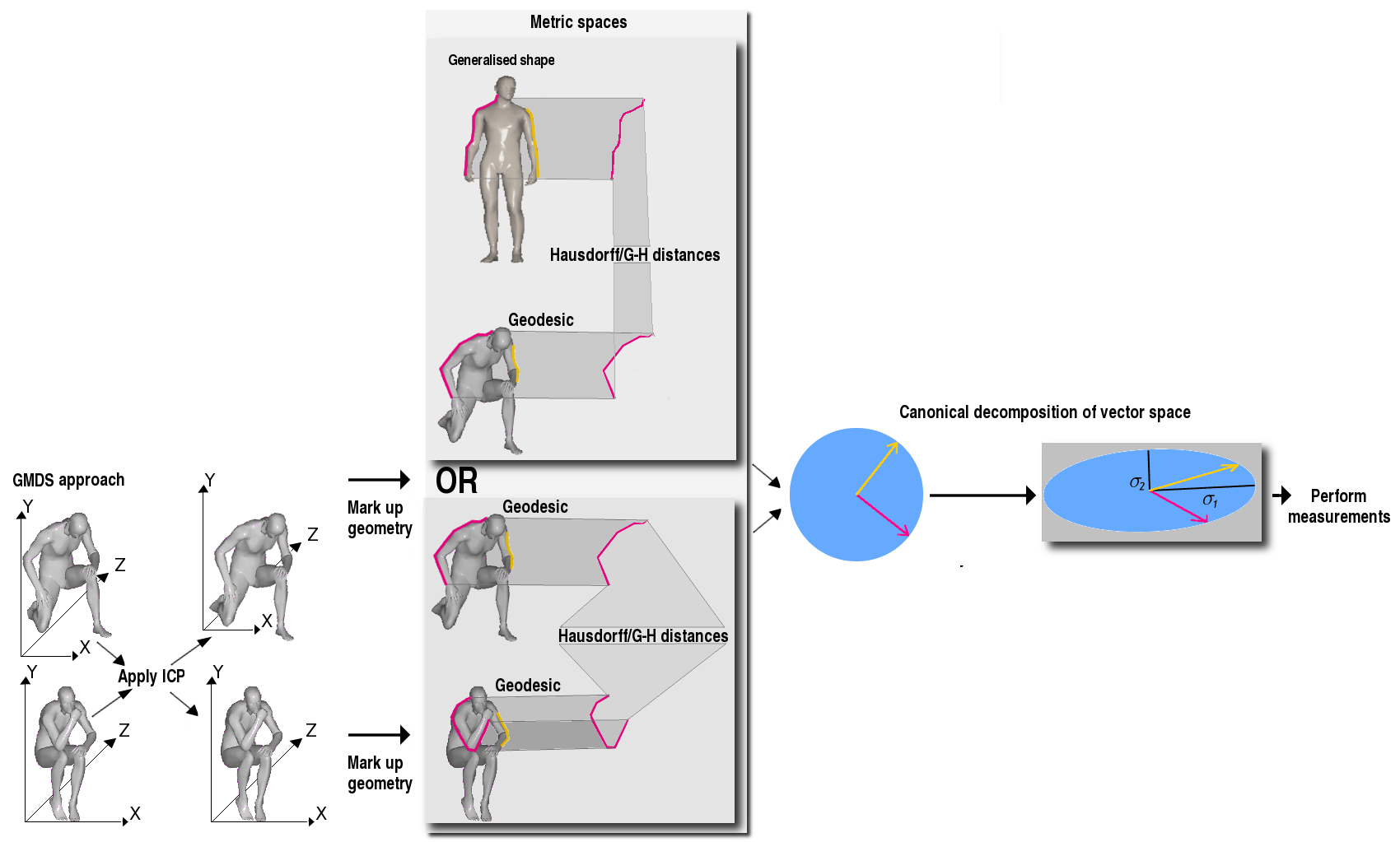
It is possible to treat it somewhat differently, e.g. use ICP for
rough alignment, GMDS for intrinsic fine alignment. If the alignment
is onto a generalised face, then spectral decomposition takes place
in the refined space - an Eigen functions of the generalised face.
We need to refine those issues, as shown in Figure .
Next up, we shall prepare a detailed explanation.
ICP could be considered Gromov-Hausdorff (G-H) in Euclidean space.
The G-H-inspired method strives to identify and then calculate minimal
distances for a group of geometric points with commonality in a more
rigid space, wherein harmonic variation occurs in inherently non-orthogonal
spaces. One way to model this type of variation and then explain its
nature would be high-dimensional decomposition, which evidently requires
that data be represented in a high-dimensional form such as vector
of coordinates, intensities, energy, or discrete/quantised G-H distances
(geometric terms). Figure provides
an example of that subtle point.
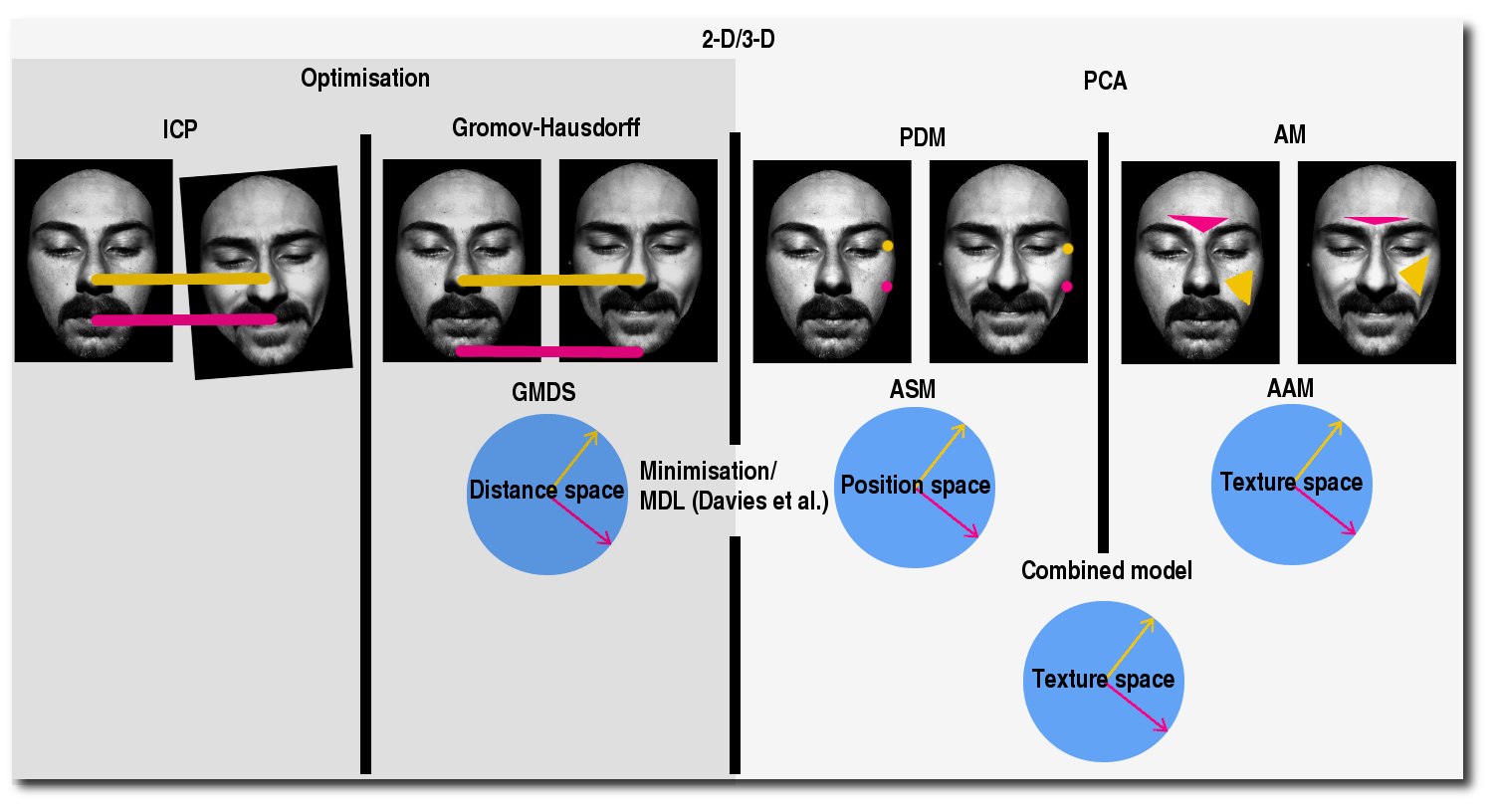
Depending on the circumstance, different measurable attributes can be added to the space, even a hybrid of them (e.g. shape and texture, so as to reconstruct/recover the relationship between image intensity and the image shape in 2- and 3-D). For synthesis of images belonging to a particular class/subspace, e.g. a canonical form (bar embedding error), one requires that the model should be specific and generic. Specific - for the fact that it need preferably not be confused with similar images belonging to another class, and generic - for the fact that it must span a sufficiently large cloud in hyperspace in order to capture the variation of all images of the same class.
As opposed to models that build upon a texture of pixels10, the GMDS approach largely discards the notion of geometry in the way the human eye perceives it; just as PCA/SVD facilitate the modeling of heat, quantifiable recipe ingredients, strings of letters and just about any parameterisable and measurable element, it should be possible to encode or at least translate a given image into a set of properties of some significant role; this is particularly attractive in 3-D, where the size of the given set can be vast - far greater than the actual entropy of the set. Considerable reduction in size can be achieved by considering distances between corresponding points or geodesic distances between neighbouring points, whereupon the image can be reconstructed by merely plugging in the modeled parameters and scaling accordingly. In that respect, it is a pseudo-dimensionality reduction problem. The elasticity of observed objects is implicitly modeled by a collection of metric measurements - measurements taken not in Euclidean space but in a more inherent space, more robust to the external viewer (judging an object from the outside and not relative to its neighbourhood (e.g. landmark points in its vicinity). Intrinsic similarities are also more resistant to error due to some topological changes in the sense that, assuming there is awareness of the topological changes typically introduced (e.g. hand touches leg), it should be possible to define 'sanity' ranges within which the distances do make sense or alternatively use diffusion distance, or intrinsic symmetry tests for something like animals where preservation of this property is expected. Euclidean distances are hardly enough for determining if two points/objects are just close to one another or actually connected.
Isometric embedding is somewhat analogous to putting an image in a reference frame from which to consistently sample parameters. As all comparisons are better off done in a spatially-neutral reference (such as a sphere onto which a more complex image is mapped/flattered), this method seems to follow the same intuition as Davies et al. who find parameters to model shape by (in 2- and 3-D) by mapping everything onto a sphere and then applying kernel functions to move those around consistently, for PCA to automatically use the ``best'' points that encode a complex shape. When dealing with modeling in this context it is typically used for segmentation, non-rigid registration, and synthesis. The problem of recognition and automated classification (e.g. telling apart extrinsic and intrinsic differences) hardly arises in this area.
In GMDS, numerical analysis and multidimensional scaling can be thought of as an iterative, concurrent search for directions and axes that better distinguish between pairs (or groups) of shapes; the general optimiser optimises over image parts and also over corresponding points, which relate to the former to an extent. When dealing with images in a metric space, the situation is merely identical or at least analogous to how image registration problems are solved, by embedment in a high-dimensional space, where the difference between them is estimated as per the vector in the manifold (Euclidean, shuffle distance, etc.), depending on the problem domain.
It ought to be possible to make the problems at hand complementary and not just mere surrogates.
When it comes to sampling geodesic distances for PCA, http://www.ceremade.dauphine.fr/ peyre/numerical-tour/tours/fastmarching_5_sampling_2d/furthest point sampling
would do the job of meaningful sampling[24]. It is 2-optimal
in sense of sampling. ![]() where distances are Euclidean
is like ICP. Roughly speaking, PCA is like SVD, being a classical
MDSearch dimension, i.e. moment by value. Thus, PCA over the geodesics
matrix (meaning MDS) could serve as initialization for the GMDS. We
need to use Euclidean distance as one feature and geodesic distance
as another. We do need a geodesic distance calculator and the same
goes for GMDS.
where distances are Euclidean
is like ICP. Roughly speaking, PCA is like SVD, being a classical
MDSearch dimension, i.e. moment by value. Thus, PCA over the geodesics
matrix (meaning MDS) could serve as initialization for the GMDS. We
need to use Euclidean distance as one feature and geodesic distance
as another. We do need a geodesic distance calculator and the same
goes for GMDS.
For cases of mis-identification we may need robust PCA variants that leave out widely different data and improve the overall model. The idea is, the distances being measured will better encompass data associated with the surface of the skin, not just mere points in a locality. Areas that are not typically changing much will be associated with low distances variation (intrinsic to the subject), whereas those subjected to expression variation will not only be expected to have high variation but the type of variation too, as measured in terms of distances, will be possible to measure and use.
Roy Schestowitz 2012-01-08