PDF version of this entire document
PDF version of this entire document




We've debugged and resolved many of the recurring crashing patterns, so experiments can now be run a lot faster, without starting a new session following each crash. A lot of parameters have also been set based on trial and error, with results being quite satisfactory even at a low resolution (which gives stability and speed).
We have run extensive experiments where the number of vertices and smoothing kernel vary so as to be more strict about local variation yet attain better spatial information and thus latch onto similar structures, respectively. It's about striking the balance between being too stringent or lenient (or false positives versus false negatives).
We will start running large experiments and share ROC curves. Comparisons of ROC curves were part of the tweaking process, but these ROC curves are neither too interesting, nor do they use more than a fixed test set on which meaningful comparisons could be made very rapidly, on a case-by-case basis too. A lot of these experiments were not important enough to merit sharing of interim results.
The experiments with 2000 vertices (and other properly set variables currently give good recognition rates. They also embrace a hybrid approach by using Euclidean measures to resolve cases of uncertainty.
The experimental set is being expanded at the moment. Having run it
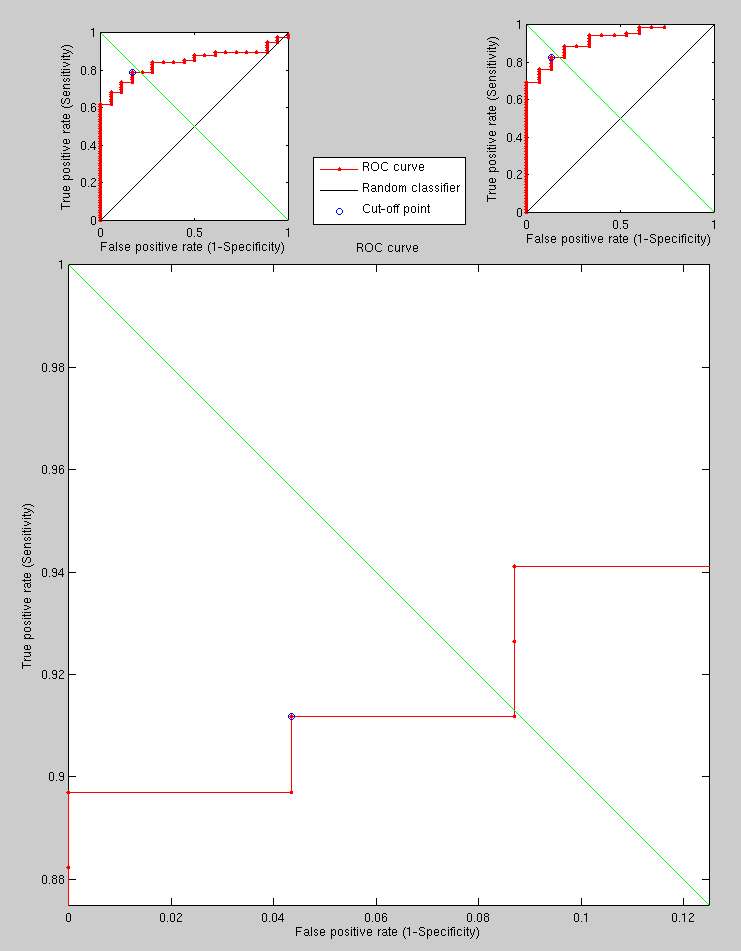
on a toy example with hard cases21 to see the effect of using a hybrid approach, we get the triplet
of curves shown in Figure ![[*]](/IMG/latex/crossref.png) . There is a lot of
room for improvement, but the purpose of this experiment was to show
the hybrid approach bringing recognition levels above 90%, which
GMDS on its own can only ever achieve with simpler data (this data
is deliberately difficult). Things will improve when proper experiments
are conducted.
. There is a lot of
room for improvement, but the purpose of this experiment was to show
the hybrid approach bringing recognition levels above 90%, which
GMDS on its own can only ever achieve with simpler data (this data
is deliberately difficult). Things will improve when proper experiments
are conducted.
|