By exploiting more information in this problem domain we can demonstrate
various things:
- ICP based on advanced geometry and richer characteristics can yield
better registration performance based on the resultant model built
with it. By varying parameters in ICP graphs can be produced help
select better value/s for particular data of greater extent. Shown
in the graph we may choose to have a level of distribution - however
we may choose to approximate it - assuming quite rightly that better
registration will yield more concise descriptions (Occam's razor principle).
- A trickier thing to do, either for technical reasons or for purely
computational limitations, is to use models as a similarity measure
in an objective function for face analysis. This can be tested on
coarser representations of faces, perhaps icon-sizes ones at a resolution
far lower than the original.
- Expression recognition or expression-agnostic face recognition can
be done using the above tools, which generally require further refinement.
Data for this is already available. However, the exact method of choice
for similarity must be strictly defined and tested systematically
for compelling validation.
By making alterations and putting them back together into the code
it was made possible to run several older variants of ICP algorithms,
incorporating them into the pipeline of the program. Older implementations
(even yours from 2008) can now be compared based on face data.
Their assessment is to be done with PCA that estimates complexity;
the drawback of this approach, however, is that is becomes slow when
the dataset is large. In the past, sets as small as 10 could be sufficient
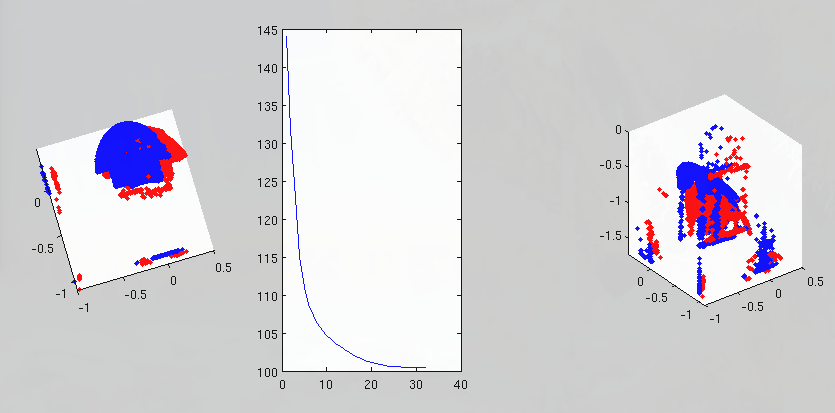
for an objective function in non-rigid registration. Figures ![[*]](/IMG/latex/crossref.png) and show the type of data we deal with.
and show the type of data we deal with.
Figure:
ExamExample points cloud for ICP
to register
|
|
Figure:
On the left: two faces (with binary masks
cropping them for rigid parts like nose and forehead) overlaid for
ICP; on the right: same from another angle
|
|
Roy Schestowitz
2012-01-08
 PDF version of this entire document
PDF version of this entire document