PDF version of this entire document
PDF version of this entire document
With the goal of validating and comparing face recognition methods, we can embark on the following path of exploration. The data to be used needs to be of different individuals and the datasets must be large enough to enable model-building tasks. As such, the data specified in Experiment 3 of FRGC 2.0 should be used for both training and testing. It needs to be manually classified, however, as groups that previously did this have not shared such metadata. It would be handy to select hundreds of faces that represent expressions like a smile and then put them in respective loader files (manual work), alongside an accompanying neutral (no expression) image. It ought to be possible to set aside 200 such pairs, all coming from different people. Identification in such a set ought to be quite challenging, without texture (which is in principle available in separate PPM files).
The experiments can have the set of 200 pairs further split into smaller groups for repetition that takes statistics into account and can yield error bars. Dividing into 5 groups of 40 pairs is one possibility, even though a set of 40 individuals is becoming a tad small. In order to train a model of expressions it ought be be possible to just use the full set.
When approaching this problem the goal would be to pair a person with an expression to the same person without the expression (or vice versa), attaining some sort of gauge of expression-resistant recognition. The gallery is the set of all faces in the set. Similarity measures being pitted for comparison here can include the 4 ICP methods we have implemented, plus variants of these and different selection of parameters. Different measures resulting from ICP and the region being compared (e.g. all face versus nose, versus forehead and nose) are another area of exploration. There ought to be separation between the idea of cropping for alignment alone and the strategy of cropping or using binary masks for the sake of computing difference as well.
What we may find is, by cropping out some parts of the face, recognition will improve considerably. But in order to take the deformable parts that change due to expression into account, something like an expression becomes necessary. Then, there is room for comparison between expression-invariant model-based recognition and recognition which is based purely on alignment. The type of alignment too, e,g. the implementation of ICP, can be compared in this way,
To summarise this more formally, we take N=200 pairs of size 480x640, where all of them are 3-D images acquired from N different subjects under various lighting, pose, and scale conditions, then register them using 4 ICP methods, in turn (potentially with variants, time permitting), using a fixed nose-finding method. As the first experiment we may wish to apply this alignment to a set of cropped faces, ensuring that they all lie in the same frame of reference. A model is built from the residual of all 200 pairs, in order to encompass the difference incurred by an expression of choice, e.g. smile or frown. In the next stage, 5 sets of M=N/5 images are set as a gallery G and a probe p goes through all images in G, attempting to find the best match best on several criteria such as model determinant or sum of differences. This is how it is implemented at the moment. To measure determinant difference it is possible to add the new residual (between p and any image in G), then concatenate it to the set of observations that build the model, rebuilding it rapidly (coarse-to-fine approach if needed). This is how it is implemented at the moment. Subsequent experiments can extend to compare other aspects of recognition using the same framework/pipeline. GMDS can also be added for comparison with G-PCA. Measurement of performance should be easy if the correct matches are recorded for a random permutation of the set and then paired for some threshold (or best match) based on the gallery. The most time-consuming task is organising the data for this set of experiments. That may sound plausible enough as a starting point.
===
If the experiments work as hoped, performing them on larger sets ought
to be trivial. To proactively remove allegations of the set being
too easy to deal with (picky-ness in peer review), the most difficult
partition when it comes to acquisition quality is taken. Figure ![[*]](/IMG/latex/crossref.png) shows some examples of pairs that are being used after being selected
as not many images contain expression variation. The selection process
of very tedious as very few 3-D images exist with expressions in them,
especially ones from the same person (required for consistent training
assuming intra-subject residues are alike for common expressions).
shows some examples of pairs that are being used after being selected
as not many images contain expression variation. The selection process
of very tedious as very few 3-D images exist with expressions in them,
especially ones from the same person (required for consistent training
assuming intra-subject residues are alike for common expressions).

|
About 5 hours were spent classifying the NIST datasets for future experiments. An initial subset of it is put in loader files. From the whole 3-D data of the Face Recognition Grand Challenge, one can only find a few hundreds of distinct individuals. Not all of them have an acquisition with a smile. I found just over 80 by manually browsing everything and some will be hard to work with due to obvious cases of degraded signal. The criteria was that all parts of the face (mouth upwards) must be visible and the expression one of happiness, not necessarily a smile.
The new methods of ICP are applied to target data such as the above.
The program works reasonably well (see Figure )
with GIP implementations of ICP (there are two main ones from GIP)
and the new data which comprises 86 pairs, or 172 images in total.
We have gone through nearly the entire group of images for the purpose of reassurance, ensuring not so systematically that without any intervention or modification the face is detected and brought into alignment, first by segmenting its parts and then by translating it to better fit the pairing (a companion image which is non-neutral). So far we have found just one problematic image, where some guy's broad locks are mistaken for the parts of his face. This will need to be corrected somehow, without treating it as a special case. It is actually surprising, given the variation inherent in this set, that the vast majority of images will be detected so easily.
If we need a single or a couple of people with various expressions, that we define somehow, it will be possible to generate in the lab. We could define the required expressions by pictures.
We already have a group of a dozen expressions, all acquired from the same young lady. In order to perform a comparison where recognition is not a binary selection problem (UWA had three subjects in their sets) we thought it would be preferable to try this algorithm on a cluster that builds a model and then also manifests galleries from the training sets. If a model-based approach can be shown to be superior to a purely geometric approach, it would concur with some previous work I did on human brain in 2- and 3-D.
The use of broad galleries of expressions taken from smaller groups would be immensely useful for experiments that check our ability to detect expressions rather than detect the person, bar expression. The paper from UWA dealt with the latter problem, wherein they present a probe with a set of possible matches and by mitigating expression differences, metrics like point-to-point distances become more meaningful (resistant to elastic deformations).
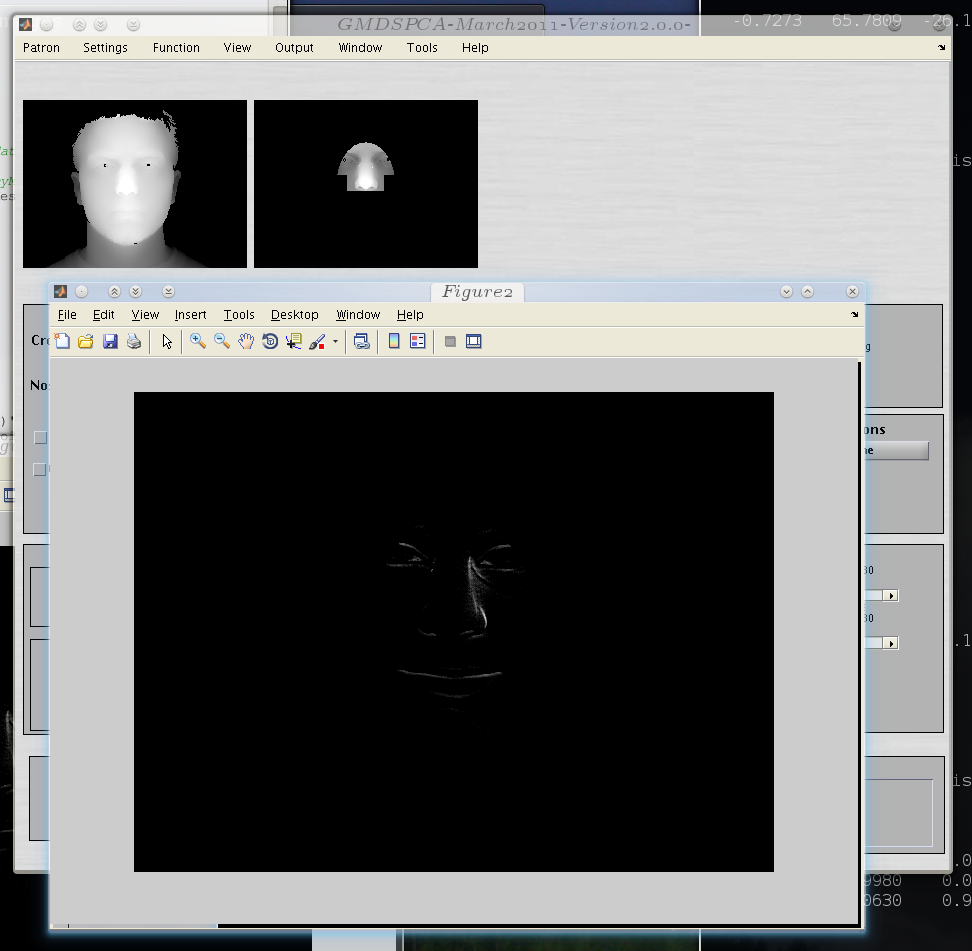
Shown in Figure is the difference
between the images from our expressions set and resultant corresponding
images following ICP-found translation. This uses a 2008 implementation
of ICP even though we have a newer one which works.

|
Several isolated images that only account for about 1% of those selected
from admittedly difficult sets cannot be deal with, at least not short
of major improvements to the algorithm, which then jeopardises handling
of all the other images. To avoid falling into such a cycle of refinement/overhaul
which is set-optimised, it is reasonable to consider cull-out. Images
such as the ones shown in Figure (the only
problematic ones found thus far) pose too much of an issue to be usable
due to the hair, which stands out and fits within the frame looking
for parts of the face. Therefore, to simplify the experiments, these
images get dropped. It still leaves faces from over 80 different people
(distinct anatomical characteristics, scale, gender, and so on).
To give examples of some of the faces we deal with (and the algorithm
deals with painlessly), see Figure which
merely shows the first 6 rather than cherry-pick good examples (everything
in the current set is handled correctly).