 PDF version of this entire document
PDF version of this entire document




The images were downsampled by a factor of 10 along each dimension,
lowering by two orders of magnitude the Z axis data that gets sampled
by PCA based on a grid. This ought to keep the models more manageable
for the purpose of algorithm/performance testing. Interestingly enough,
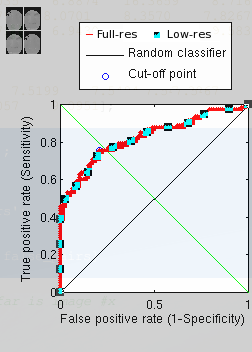
downsampling hardly affected the ability to recognise faces. As Figure
![[*]](/IMG/latex/crossref.png) shows, the classification remained almost
the same, even though the images were tiny (see Figure
at the top left).
shows, the classification remained almost
the same, even though the images were tiny (see Figure
at the top left).
|
The differences are very minor since the current performances are not within the expected (state of the art) results. Much better results could be expected (if, for example, at 0.01 false positive rate we get about 0.6 true positive). With GMDS, for example Bar Shalem got about 0.9++ for sampled NIST database.
It would be surprising if our current recognition rate was high because the points compared are sampled around the lower part of the face and all of them are neutral-to-non-neutral (or vice versa), so the mouths move. There is nothing to annul this at present. Next, we a model of fine-scale image equivalents and will have some ROC curves. We deliberately chose the most difficult tests (not working in the high 90s/99th percentile).