PDF version of this entire document
PDF version of this entire document
Results have changed somewhat after making big changes to the code, mostly in order to improve performance and also address some errors. Bugs were introduced as part of these changes, leading to a slow debugging process and some basic assessment stages that helped guide development. It's cleaner now and it contains more modes of exploration.
Reasons for lower performance than what is possible include a need
for improvement in location, addressing for example the almost problematic
pair in (see Figure ![[*]](/IMG/latex/crossref.png) ) To test performance
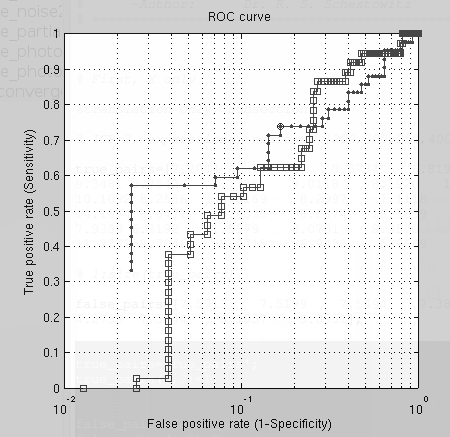
in a quick way, half the set (first half) was used to yield a ROC
curve, or two as shown in Figure . Shown
with diamonds as markers are the older results and the matrix of many
images (Figure ) shows
the type of masks being used to to classify unseen non-neutral images
(hardest task).
) To test performance
in a quick way, half the set (first half) was used to yield a ROC
curve, or two as shown in Figure . Shown
with diamonds as markers are the older results and the matrix of many
images (Figure ) shows
the type of masks being used to to classify unseen non-neutral images
(hardest task).
The next comparisons will be more interesting as they will involve different strategies. The aim is to measure expressions-resistant properties using eigenvectors or geodesic distances. The harder the test set, the more profound the performance advantage will seem.

|
With a broader facial range of view (bigger face-imposed mask, display
of residues and partial image selection), smoothing significantly
increased, the use of GIP's geometric ICP, and after bug removal (ICP
totally disabled for testing purposes as well), median of quadratic
differences was replaced by average of quadratic differences, we have
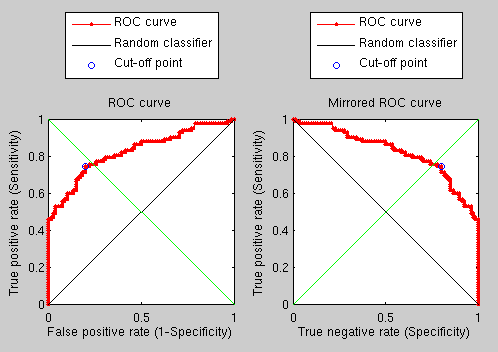
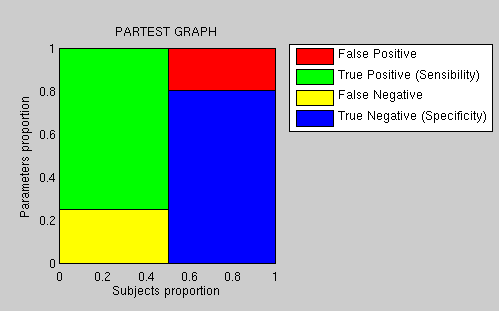
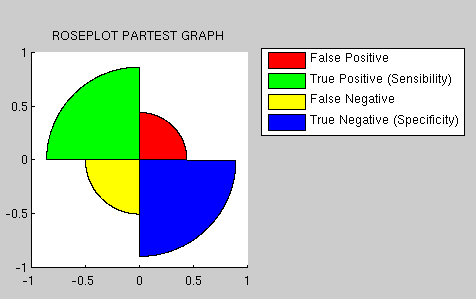
rerun some experiments (the results can be seen in Figure )
and spent 3 hours (in vain) trying to build a model from the whole
set. When it came to PCA, the program just took over 4 GB of RAM (including
swap) and never completed the operation. It hanged for 6 hours, so
this needed to be aborted. The GIP dataset comprising smiles from
one person (young female) could be used instead, however the image
dimensions and the nature of the images is slightly different there.
Treating these two sets interchangeably would not be so trivial. For
this set where all the pairs comprise one neutral and one non-neutral,
the absolute differences are not so meaningful, as expected. But the
removal of expression very much depends on the quality of the model
and the recipe for building it counts a lot. It seems as though MATLAB
exceeds some memory thresholds even with 166 images where the points
are densely sampled. This necessitates a redesign. For testing purposes
we will start down-sampling the images by sampling at equally spaced
points on a grid. This can speed up experiments and when everything
works satisfactorily, every component in the pipeline can be scaled
up again, maybe even applied in a multi-resolution-type approach,
as done with Active Appearance Models (AAMs) for performance gains.
|
Roy Schestowitz 2012-01-08