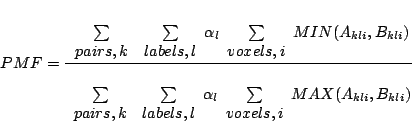PDF version of this document
PDF version of this document



data description: xxxxx
The first of the proposed methods assesses registration as the spatial overlap, defined using Tanimoto's formulation of corresponding regions in the registered images. The correspondence is defined by labels of distinct image regions (in this case brain tissue classes), produced by manual mark-up of the original images (ground-truth labels). A correctly registered image set will exhibit high relative overlap between corresponding brain structures in different images and, in the opposite case, low overlap with non-corresponding structures. A generalised overlap measure [1] is used to compute a single figure of merit for the overall overlap of all labels over all subjects.
where ![]() indexes voxels in the registered images,
indexes voxels in the registered images, ![]() indexes the
label and
indexes the
label and ![]() indexes the two images under consideration.
indexes the two images under consideration. ![]() and
and ![]() represent voxel label values in a pair of registered
images and are in the range [0, 1]. The
represent voxel label values in a pair of registered
images and are in the range [0, 1]. The ![]() and
and ![]() operators are standard results for the intersection and union of a
fuzzy set. This generalised overlap measures the consistency with
which each set of labels partitions the image volume. The parameter
operators are standard results for the intersection and union of a
fuzzy set. This generalised overlap measures the consistency with
which each set of labels partitions the image volume. The parameter
![]() affects the relative weighting of different labels.
With
affects the relative weighting of different labels.
With ![]() , label contributions are implicitly volume weighted
with respect to one another. We have also considered the cases where
, label contributions are implicitly volume weighted
with respect to one another. We have also considered the cases where
![]() weights for the inverse label volume (which makes the
relative weighting of different labels equal), where
weights for the inverse label volume (which makes the
relative weighting of different labels equal), where ![]() weights for the inverse label volume squared (which gives labels of
smaller volume higher weighting) and where
weights for the inverse label volume squared (which gives labels of
smaller volume higher weighting) and where ![]() weights for
a measure of label complexity (which we define arbitrarily as the
mean absolute voxel intensity gradient in the label).
weights for
a measure of label complexity (which we define arbitrarily as the
mean absolute voxel intensity gradient in the label).
The second method assesses registration as the quality of a generative, statistical appearance model, constructed from registered images. The idea is that a correct registration produces a true dense correspondence between the images, resulting in a better statistical appearance model of the images.
Fig. 1. The effect of varying the first model
parameter of a brain appearance model by ![]() standard deviations.
standard deviations.
Fig. 4. The calculation of Fig. 5. An example of the shuffle difference
a shuffle difference image image (right) when applied to two MR slices (left)
Fig. 3. The model evaluation framework. Fig. 2. Training set and model
Each image in the training set is compared synthesis in hyperspace
against every image generated by the model
Fig. 6. Specificity and Generalisation for increasing mis-registration of different shuffle neighbourhood sizes.
Fig. 8. Appearance model which was built automatically
by group-wise registration. First mode is shown, ![]() standard
deviations.
standard
deviations.
To test the validity of the proposed methods, the brain images were annotated with 6 tissue classes including gray, white matter and CSF that provided the ground truth for image correspondence. Initially, the images were brought into alignment using an NRR algorithm based on the MDL optimisation. A test set of different registrations was then created by applying random perturbations to each image in the registered set using diffeomorphic clamped-plate splines. By choosing a different perturbation seed for each image and gradually increasing the magnitude of the perturbations, a series of image sets of progressively worse spatial correspondence and thus registration quality were obtained. By measuring the quality of the registration at each step, the proposed registration assessment measures can be validated.