- Expression parameterisation in action (image from
Al-Osaimi et al.)
- The effect of varying the first (top row),
second, and third parameter of a brain appearance model by
 standard deviations
standard deviations
- The analysis performed by a Robust
Generalised PCA algorithm
- The proposed framework for GMDS
improvement
- A closer look at the GMDS approach
- Crude visual example of how typical
PCA and GMDS relate to one another, approach-wise
- Example face from the FRGC dataset
- 3-DImage example from the FRGC dataset,
demonstrating points on the side of the face - points which need
to be removed
- Example face with holes remaining in the data
- Another example
- Same as above, different angle
- Program steps broken down into an
overview-type flowchart
- Areplotted block diagram of the components
in the IJCV paper (top) and our proposed extension/modifications (bottom),
and the already-implemented procedures
- Translation of the given (cropped)
face applied so as to position it with the nose tip at the front and
at the centre
- A before/after overview
- Early prototype of the GUI
- The same GUI at a later date
- The shape-residual extracted from two different
images of different people, where the faces are aligned so as to fit
a common frame of reference.
- A sample image and a corresponding residual
wrt to another (unseen) image
- Example of what happens when the nose
is incorrectly identified
- Examples of challenging residuals
that have a lot of noise
- Process of cleaning up the residual
of two images (GIP data)
- Examples of residual images before
and after outliers removal
- Examples of faces that, given the default
set of parameters, do not detect the nose correctly (with old-style
cropping)
- Improved cropping of faces that takes
spatial measurements into account
- Example of binary masks being applied
to image residue
- Examples of 4 raw residuals being reduced
(notice the Z scale) using thresholds and masks
- Cropping of GIP data shown on the top
left
- Model modes decomposed for a couple
of GIP datasets (abbreviated to account for top 10 modes alone)
- Example 3-D representation
of an arbitrary face image from FRGC 2.0
- Example of alignment and cropping of the
rigid parts of another face (mind axes scale) with the result shown
at the top surface and right image inside the GUI
- Example of alignment and cropping of the
rigid parts of another face with the result shown at the top surface
and right image inside the GUI
- Example of alignment and cropping of the
rigid parts of another face there there is some noise and hole that
pose a challenge
- Decomposition based on sample GIP
data (Pareto)
- Decomposition based on just 4
registered faces with different expressions (Pareto)
- Same as prior figures, but with 90 images
in the set
- Overview of an experiment dealing with
expression-to-expression variation model-building
- The masks used to crop residuals in the
FRGC dataset. The left-hand one is more restrictive and selective
in the sense that it omits some of the data associated with the face
near the edges.
- The top row shows images of the same subject
and the bottom one is a group of hard cases (image from Huang et
at.)
- Left to right: Texture image mapped to
2-D, 3-D representation, and cropped parts (for alignment)
- Example of an image where the face does
not fit the image frame, unlike the example at the top right
- Image residue incorrectly cropped
by a binary mask
- Examples of image residues from the
FRGC datasets
- Image residues from the FRGC datasets
shown from frontal angle
- The image shows a matrix corresponding
to two things; on the left there is a top-down view of what is shown
on the right. The top part shows how the 15,000 sampled (cloud)points
get distributed after dimensionality reduction and the bottom part
relates to the magnitude of the principal components, where the red
parts show higher deviation from the mean. It is fairly smooth.
- Principal components as a function
of datapoints (log scale)
- Point-to-point correlation
along the 10th utmost principal axis
- Score per sample point, mapped back from
vectorised form to the image grid
- The tenth principal component derived
from PCA, as visualised based on the reshaped (previously vectorised)
image residues
- The tenth image residual from the Experiment
3-built EDM projected onto the EDM space's most significant component
- Example of an evaluation experiment for
photometric ICP
- ExamExample points cloud for ICP
to register
- On the left: two faces (with binary masks
cropping them for rigid parts like nose and forehead) overlaid for
ICP; on the right: same from another angle
- Examples of the faces used tor training
and recognition, with neutrals on the left and smiles on the right
- Examples of the program with the new
data and methods in place
- Pixel-wise difference between
the images from our expressions set and resultant corresponding images
following ICP-found translation
- The two images that automatic detection
struggles with (because of the hair)
- The first six neutral images taken from
the set and cropped by the algorithm correctly
- The first 6 images in the set with a narrow
mask used to extract and attain a neutral-to-non-neutral residue
- Same as the previous figure, but with only
5 images. The top row shows the effect of using a broader mask and
the bottom part shows the effect of applying a fixed mask and thresholds
to make the data more trivially comparable.
- ROC curves plotted for just 13 tests
done on the FRGC datasets with expressions isolated
- Preliminary test where several
images (not complete set) are used to get a rough idea of what the
ROC curves will look like
- A somewhat larger test on non-neutral
sets, where ICP based on PCA is used for alignment, then mean of residuals
get used as a similarity measure
- The same type of comparison with the same
type of set (as in Figure
![[*]](/IMG/latex/crossref.png) ) but with a
more cunning similarity measure and an example of the X data at the
bottom right
) but with a
more cunning similarity measure and an example of the X data at the
bottom right
- A combined view of X, Y, Z, the image
before ICP, after ICP, and the reference image
- Difference images of the first 5
pairs taken from the same people
- Difference images of the first
12 pairs taken from different people
- ROC curve of the 17 images from figures
and
- The curve showing the performance for
83 pairs from false matches and 37 from true matches
- Images ~/NIST/FRGC-2.0-dist/nd1/Fall2003range/04557d337.abs
and ~/NIST/FRGC-2.0-dist/nd1/Fall2003range/04557d339.abs,
where there is some detection difficulty
- Example face-to-face
comparisons
- The ROC curves comparison on he left as
linear scale and on the right log-scaled
- The results in terms of recognition rate
after widening the mask and also changing from median to mean
- The results from full-resolution image
sets and low-resolution equivalents (as seen at the top left)
- The FP analysis of the results of a model-based
approach, with the breakdown of modes shown at the top right
- Performance comparison
between an approach where the median of squared differences gets compared
to mean of model changes
- Performance of recognition
when the absolute differences are gathered by their median
- Performance of recognition
when the squared differences are gathered by their means
- Degraded performance when the
compared face pairs are not ones that were used to train the PCA model
- Comparison assessment with a large set of false pairs. The results
of random pairs versus unseen pairs with expression differences.
- The results of matching random pairs from different people and from
similar people, with and without expression (based on expression models)
- The results of comparing correct pairs
to random (and false) pairs using the model-based approach. The right
hand side shows the breakdown of model modes.
- Performance measured on relatively
small sets, empirically showing that coarser grids yield better recognition
performance
- Decomposition of the different modes
of variation for the three cases, namely granularity levels 6x6, 8x8,
and 10x10, respectively (10 pixels/voxels apart) demonstrating that
despite the changes in resolution the model modes have a similar distribution
and are probably inherently similar, as expected
- Comparison between the performance
of the method with smoothing applied before sampling and without any
smoothing at all (which gives similar performance)
- The decomposition of the model as
a chart corresponding to Figure on
the right, this time with smoothing on
- The first few face residues following alignment
with ICP (sample points being around the forehead, nose, and eyes)
- The results of measuring the similarity
by determinant of the eigenvalues of the covariance matrix and engaging
in a recognition task
- Results of an experiment where the determinant
is again being explored, this time with a larger set
- Results of an experiment where the determinant
is again being explored with a comparison of the curves for 3 values
of
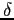
- The result - in terms of performance -
of varying
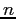 in
in
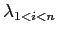
- The effect of changing the value of
on the overall recognition performance
- An 8x8 separation between points in
the image (shown from two angles), with downsampling done for debugging
purposes
- A slice or subset of the data being used for
ICP (on the left) and the masked face from which it is extracted (right)
- Top: Two images taken from the
same individual being compared when there is insufficient compensation
for noise. Bottom: another set of such images but where smoothing
is applied to reduce noise-imposed anomalies
- On the left: the result of poor or buggy
ICP (difference); on the right, an image is shown of the type of image
we expect to have and also get when ICP performs well
- Difference between the first 4
images before and after ICP (rotation and translation), with two of
the first reference images shown at the bottom just for a sense of
what the images at the top are derived from
- The effect of the bug demonstrated by
showing misalignment on the X axis (and to a lesser degree in Y too).
- The new distribution of modes following
the bugfix
- The effect of perturbing the points on
ICP
- The effect of noise on ICP studied by
aligning images 1-5 at the top to images 6-10 at the bottom
- The purely median-based performance
on the Spring Semester set, without ICP
- The purely model-based (determinant)
performance on the Spring Semester set, without ICP
- Example differences between
an image before and after translation (in all three dimensions)
- On the left: the results from a test run
(first 20 images) using the determinant-based objective function.
The model was not constructed with translation, whereas matching did.
On the right: the same but with a median-based similarity measure.
- A top-to-bottom view of one's face
(the rigid part) with corresponding translation and rotation
- A look at some of the tweaking and debugging
process of ICP, where the angle shown is pointing from underneath
the nose, going towards the top
- An example of the first image pair, visualised
separately as stripes as coarse as the image sampling rate (for the
model)
- The results of a mis-constructed experiment
where ICP did not work correctly and nonetheless, the model-based
approach did not fail so miserably
- Aligned and misaligned derivative
difference (Y only)
- Multi-feature experimental
data (y-only derivative)
- Y derivative (left) and X derivatives
(right)
- A couple of faces with the Y derivative on
the left and the X derivative of the Y derivative (result of a bug)
on rte right
- An example Y derivative image before (left)
and after (right) signal enhancement
- The result of a very crude experiment on
Fall Semester datasets, which build a PCA model of derivative differences
and then perform recognition tasks on unseen faces. ROC curves are
shown on the left, the composition of the model is abstracted on the
right.
- The result of a buggy code creeping into
experiment as in (incorrect values were
sampled). ROC curves are shown on the Left, the composition of the
model is abstracted on the right.
- The result of a correct code dealing with
an experiment like in but with data from
the Fall Semester
- The effect of stress minimisation of the
shape of a cat
- Randomly chosen face sampled 10 point
apart along each dimension
- Example of almost randomly selected
distances along the shapes
- Improved selection of distances
(787 vertices) and the effect of MDS reducing the stress
- Top: original image. Bottom (from
top to bottom, left to right): stress minimisation with MDS, one iteration
at a time
- A look at the cruder among ways to perform
a comparison between faces
- An exploratory look at how applying
MDS to face images of the same subject depends on presupplied distances
- Transformation from 3-D face (left)
to a subset of rigid parts and then GMDS handling of the underlying
surface (right)
- Nose and eye regions from different people
(FRGC 2.0) as treated by GMDS (
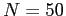 )
)
- Nose and eye regions from different people
(FRGC 2.0) as treated by GMDS when
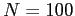
- Nose and eye regions of the same person
(FRGC 2.0) as treated by GMDS
- The first pair in the set of real matches
(same person in different poses)
- An example of a problematic pair with
a false signal spike (left)
- A view of the program's front end (framework
wrapper)
- A view of the handling of image pairs and their
comparison using GMDS
- A simple visualisation of the algorithm's
processing of images, by numbers
- The correspondence problem
in GMDS and an abstraction of the data by consideration of a top-down
representation
- Performance tests on very basic GMDS
algorithm applied to rigid face parts
- Examples of some of the bugs encountered
and overcome while working on GMDS implementation for faces
- Set of results for 10x10 grid sampling
(GMDS)
- Early performance measures
for GMDS more properly done
- Larger scale examples of early performance
measures
- Results from poor PCA model, obtained
using GMDS
- Model modes distribution, corresponding
to Figure
- Model modes distributions (of
10 people and 76 people), built with the proper weight, albeit with
very heavy and sometimes excessive smoothing
- Preliminary results from GMDS-based
recognition with full face surface
- A look at an alternative mask which focuses
on the nose and inner eye only
- Recognition results based on
the mask from with GMDS
- A nose-only mask, which omits areas
with potential of facial hair (the examples at the centre and the
left are not related)
- The performance attained by applying
GMDS just to the nose region
- Example of the effect of ICP-induced rotation
on the Voronoi cells
- Return to the old mask with additional rotation,
which does not yield better results than those at the region of 92%-98%
recognition rate
- Cheek inclusion gradually staged
in for understanding of its impact on recognition performance (geodesics
and PCA)
- The stress map corresponding to the new
binary mask (with 150 points for FMM)
- Stress map and the corresponding faces
(looking from beneath the nose) from which it is derived
- An example of a false pair (different
people) and a cleaned up stress map showing some interesting patterns
- Another example of a false pair and
the results of GMDS
- Example of a bug found in the program, leading
to massively false correspondence upon the same person
- An example of acceptable matching between
two poses of the same person
- Another example of a bug found (and
resolved) after it had proven problematic to recognition rates
- A look at the problem associated with narrow
faces that lead to incompatible sampling
- General program settings used
for the subsequent experiments
- Results of a large-scale test after previous
bugfixes
- Example of a correspondence problem in
a pair of images (one image on the left, another on the right). The
top 4 images show the correspondence after the bugfix for one pair
and the bottom 4 show the outcome of applying a fix to another pair.
- Example of a problematic pair where hair
obstruction and nose position compared to the forehead caused an issue
which is now properly addressed
- Example of a pair where the side of the
face got sampled, leading to serious issues (top) before they got
resolved (bottom)
- Comparison between images of
the same person, where the height of the nose relative to the cropping
is causing issues
- The images corresponding to the
above example (same person, different positions)
- Another example of a problematic
example where the score borders on being seen as ``no match''
even though it is
- Some recognition results from
the above experiments, with denser sample on the right where the cheeks
were also remove to test their impact on performance (little impact)
- Smaller-scale and large-scale
(right) experiments that look at how applying the methods only to
the training set (many identical faces clustered together) changes
the above results. It does not affect them much.
- Standard program settings with
which to run the Texas data
- An example of GMDS applied to just a vertical
slice of the data taken from different individuals
- Exploratory work around GMDS applied
solely to the nose region of different people (left and right), shown
from different angles
- Initial experiments with the
Texas3DFR Database excluded the cheeks, which were later added as
various parameters were studied for their impact
- Texas3DFR Database pairs with
the correct correspondence
- Model modes with more than 1% variation
built from correct pairs
- Model modes with more than 1% variation
built from false pairs
- With GMDS issues still in tact, the ROC
curve for recognition suffers
- A pair that GMDS usually fails on
- Another pair that GMDS usually fails
on
- A closer, GMDS-style look on the
very flawed correspondence-finding (example from Figure )
- Another example of a GMDS-type comparison
applied to a real pair and failing
- Pairs of facial expressions from the same
person, cut in half beneath the nose and tilted sideways, then shown
with GMDS applied. The score (from left to right): 3.4866, 2.4497,
2.4718, 10.9726, and 173.6779
- Some of the raw images (full face) after GMDS
with 50 Voronoi cells displayed
- A top-down view showing the matching and
the corresponding score. with flipping manually corrected. The third
example from the top got the topology completely upside down.
- 5 examples of experiments with synthetic
data, where the top part shows the pair of images in their classic
form, the middle shows a top-down view, and the bottom part is the
range image
- The scores in black show the pairings between
different people and in green are the scores of matches between the
same person
- A new visualisation form where the
dots signify stress at the given point
- Top: A mapping of GMDS stress
when cheeks are included in match-finding. Bottom: same as
above but cheeks excluded. One can assume dark means low stress and
white is high stress.
- Original images, erroneous
cropping effects (still in the process of debugging) and retriangulation
of the points after omission.
- A toy example of a very small couple of
surfaces cropped from the centre of a face of the same person, where
the pairs shown correspond to top-down view and GMDS' results
- Example of an augmented slice from a pair
of faces and GMDS applied to these
- Results of a comparison between arbitrary
bits where some boundaries are a Euclidean cutoff and some are geodesic
- Results of a comparison between consistently
chosen bits (near the eye) where some boundaries are a Euclidean cutoff
and some are geodesic
- Results of a comparison between surfaces
that are mostly carved out of a geodesic boundary
- Results of a comparison between noses with
a boundary defined by geodesic distance constraints
- A preliminary look at a predominantly
geodesic mask and how it separates pairs from different people (top)
and pairs from the same person (bottom)
- An experimentation with a mask
that includes points around the forehead and around the nose
- With just 600 vertices, the ROC curve shows
unimpressive ability to distinguish between true pairs and false pairs
- The effect of increasing the number of
vertices to 2420.
- Improved performance with slight
changes in surface size for the gallery
- The result of changing the border threshold
for surface carving
- The result of growing the surface too
big
- Performance with (left) and without
averaging (right) of the arrange image for better sampling of the
GMDS process
- A look at slicing at geodesic boundaries around
the nose tip, with coarse resolution on the left and improved resolution
that isolates regions on the right
- Newer Fast Marching algorithm as applies
to a face from the Texas database
- Newer Fast Marching algorithm as
applies to TOSCO dataset
- A bug with connected triangles
- Two faces and the issue with triangulation
- The data (top) and the inherent bug which
incorrectly connects points (bottom)
- A correctly connected pair of faces
with the source point highlighted
- GMDS using the older FMM implementation
superimposed on top of new and incompatible code
- Visualisation of the increasing number
of vertices
- Coarse resolution performance
compared
- A finer resolution-oriented
set of results obtained from fewer runs than before
- An example where the hair entering the
surfaces can interfere with GMDS-based recognition (GMDS as a similarity
measure)
- Example where hair is at risk as being
treated like skin surface, depending on the mask/s
- The result of the nose tip being misplaced
(original on the left, after masking on the right)
- The problem of non-overlapping faces, a
result of misregistration/misalignment
- Registered and correctly aligned
image
- Example of a correctly sliced image subset
(before geodesic boundaries cutoff)
- High-density (vertices)
surface and the images it is carved off
- Problematic image pairs
- A pair that causes GMDS to fail
- Problematic real pair (same person)
where GMDS works but poorly so
- A 3-D representation of a pair of
images from the same person
- GMDS failing to work as expected
- A problematic pair which is seen as
too different to quality as a match
- ROC curve based on the smoothed surfaces
variant of the algorithm
- Example of some GMDS (mis)matches in the
initial experiments
- ROC curve based on the improved smoothed
surfaces and somewhat better resolution
- 3 problematic image pairs
- The area of collision in GMDS-based face detection
- Examples of shape pair residuals and the corresponding ROC curve
- Residual difference and the problem of localised high signal (which
makes this a weak similarity measure)
- ROC curve obtained by using a residuals of just a particular image
region (nose and eyes)
- Examples of pixel differences for pairs
of the same people
- ROC curve corresponding to pixel
differences for the whole middle section of the face
- ROC curve corresponding to pixel
differences for the nose area alone
- ROC curve corresponding to sum
of squared differences for the nose area alone
- Example of 2 pairs from which the difference
image is produced (shown at the top)
- Top images show the sum-of-squared-differences of the first 3 true
pairs, with the mere difference shown at the bottom
- Examples of the first 12 false pairs (sum-of-squared-differences)
- ROC curve generated by a sum-of-squared-differences-based similarity
measure
- ROC curve generated by a sum-of-squared-differences-based
similarity measure
- Examples of matches between true
pairs and other matches between false
pairs (different people). The separation is not yet profound enough
to get state-of-the-art recognition performance.
- Example of similarity values after a Euclidean delimiter (above the
eyes) was removed
- Example of similarity values with more points
- Number of points pushed higher towards 350 (near the maximal allowed
value)
- Pairing examples with false pairs, 1000 vertices on each
- Pairing examples with false pairs, 2000 vertices on each
- At the top left is just a naive implementation,
the top right shows what happens when GMDS failures get detected and
removed, and the large plot shows what happens when Euclidean measures
are factored into this toy example.
- 4 problematic image pairs
- Manually-measured width
values for pairs of faces corresponding to different people
- Manually-measured width
values for pairs of faces corresponding to the same person
- A geodesic ring/circle-based
measurement as applied to tell apart anatomical equivalents from inequivalents
- FMM is being used in a level sets-esque approach
- An extension of the original (first) experiment which explored FMM
(with Euclidean measures) as a classifier
- Results from an extension of the range of radii/distances traversed
from 20 to 50
- Interim results (70 images) show 95% recognition rate with FMM-only
(no GMDS) utility, but this tends to degrade as more difficult images
are presented. Two good recognisers (classifiers), one of which is
a Euclidean-geodesic hybrid, might give pretty good and mutually-independent
results without using texture or fiducial points.
- An example of two images from two different
people, which nonetheless the FMM-based recogniser cannot quite detect
as being different
- An FMM-based recogniser results
in nearly 90% recognition rate now (without GMDS)
- The FMM recogniser ROC curve after
increasing the number of true pairs
- Example of a 10 degrees tilt
- Recognition results from tilting one corresponding eye 360 degrees,
then measuring distances on the geodesic boundaries
- ROC curve based on comparing 220 images, where their Euclidean properties
are measured upon geodetic slices
- Brute force implementation that measures many geodesic distances
- This figure visualises the idea
of encoding surfaces as a vector not of surface vertices but an ordered
list of Euclidean-upon-geodesic distances, which are fast to compute
and sensitive to isometric/mildly detectable alterations
- Separability testing in hyperspace
- The image set of the first imaged individual in then test
set, as an animation. The animation of the data from the 95th person
is originally a GIF file.
- Animation of the data from the 96th person
- ROC curve obtained by measuring geodesic-Euclidean
distances on the first imaged individual vs the same on different
individuals
- Smoothing versus no smoothing before measuring distances for
identification purposes
- The result of running the test set further (not for comparative purposes)
- Animation of the data from the 103rd person. It is based
on a set of images from the same person (numbered 103), without particularly
challenging variation
- The ROC curves based on a comparison between arbitrary (non-identical)
pairs and pairs of images from the 103th person
- The results following an increase in the smoothing range, demonstrating
significantly degraded performance
- An illustration by example of some images that prove to be challenging
in the sense that their intrinsic properties are so similar that they
almost get classified as being the same person (depending on how the
threshold gets set)
- Detection rate of my FMM-based method without GMDS as fallback (just
annulling cases where fallback is invoked). X is log-scaled.
- Results of GMDS applied to one single region rather than many, demonstrating
the importance of having enough samples
- FMM-based method without the use of ranges for fallback (and with
some errors in pairs, which degrades the quality)
- The result of applying the new method to pairs it feels confident
enough comparing, based on pre-supplied thresholds
- The problem with GMDS not finding a path through the graph in some
cases, where eye regions get altogether cropped out as a result
- The performance one gets by handing difficult cases based on nose
alone or eyes alone. The results from GMDS are similar to the results
attained using the other method which is still undergoing development
and gradual improvements, maybe with exact geodesics.
- The performance attained by removing hard cases
- The performance attained by changing the number of vertices and keeping
all pair examples to be judged for similarity
- Example of poor alignment in the original set
- Two examples of easy matches from the remainder of the dataset (which
was enrolled in its entirety into the experiment)
- Example of geodesic differences map around the nose (to be improved)
- Example of a thin FMM spiral
- Four small examples of distances spiral in isolation
- 2 larger examples of distances derived from pairs of images of the
same people
- The distances spiral overlaid on the images it corresponds to (9th
person in the set)
- The distances spiral overlaid on the images it corresponds to (13th
person in the set)
- The distances spiral with larger,
clearer points
- Example of a true pair (same person) with a simplified representation
of distances around each source point (FMM)
- Another example of a true pair with simplified representation of distances
around each source point (FMM)
- An expanded view on the mis-correspondence between regions, where
brighter shades represent greater disagreement between the pair taken
from the same person
- An expanded view on the mis-correspondence between regions, where
the pair taken is from different people
- Overview of the debugging process with examples from two true pairs
(same person) and one false pair (different people), with the eye
component discrepancies shown at the top and the nose at the bottom
- The ROC curve obtained by using a weighted form of the similarity
measure
- ROC curve for the first phase of the experiment, which compares one-to-one
(same person) and many-to-many (different people excluding this person,
except in one case)
- A broader scope curve for performance
as in the previous figure
- An example of misalignment in some parts of the nose in a true pair
of images (same person), with the left nostril being a prime example
- An example of a borderline case (leaning towards false positive)
- Debugging information for the problematic true pair shown before
- Debugging information (distance differences) for the aforementioned
false positive
- The problematic (borderline) false positive after the new alignment
scheme gets applied
- A contour around nose tip candidates all of which share the same (maximal)
depth value, resulting in uncertainty
- The Performance attained in hard cases where the tip is determined
more arbitrarily than in a sophisticated fashion
- The Performance attained in hard cases where the tip is chosen based
on the average location of tip candidates
- The result of applying a faster calculation of similarity, as applied
to the first person against 90 different pairs from 90 different people
- Performance when smoothing gets disabled, demonstrating little difference
compared to prior results
- The sort of results we get by using spectral masks without proper
adjustment to make the masks shrewd enough. There is some potential
there.
- Example raw slice of the face of one subject
- A test run with just one ring around the nose as a discriminant
- The ROC curve obtained by using one single spectral/diffusion ring
- The ROC curve obtained by using one single spectral/diffusion ring,
applied only to the true positive gallery in the set
- The ROC curve obtained by using just one diffusion distance as a discriminant
- The ROC curve obtained by using two diffusion distances as discriminants
- ROC curve for a rather disappointing approach of mask dilation based
on diffusion distance
- The same GUI in late March
- Face cropping for standard experiments data
- Difficulties identifying faces in GIP data
- Difference images of the entire face surface before
and after ICP-based registration
- Assumed mark (left) extracted from accompanying
GIP data (right), illustrating mis-detection
- The offset problem visualised
- The face before (left) and after cropping (right)
``The surest way to corrupt a youth is to instruct
him to hold in higher esteem those who think alike than those who
think differently.''
- Friedrich Nietzsche.
Roy Schestowitz
2012-01-08
 PDF version of this entire document
PDF version of this entire document



