 HIS post is part of a series that explores the potential of comparing surfaces using GMDS, or generalised multidimensional scaling.
HIS post is part of a series that explores the potential of comparing surfaces using GMDS, or generalised multidimensional scaling.
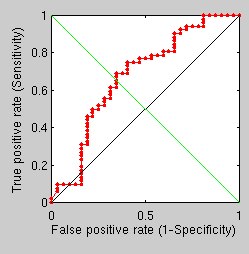
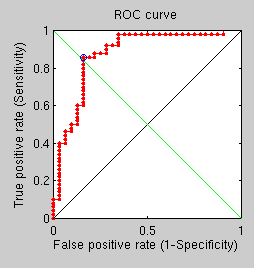
A 15-level multi-resolution approach has led to no classification errors being made, at least thus far. This may have helped prevent the convergence near local minima, but it is painfully slow, especially when the C++ implementation does not get used. I have looked into more ways to widen the separation between correct pairs (same person) and incorrect pairs. I have begun looking at the impact of two factors; one is the size of the mask used prior to GMDS (or dilation through iteration) and another is the number of multi-resolution levels. Based on an ongoing experiment, a very coarse correspondence/initialisation leads to something quite reasonable when the pairs belong to the same subject and everything is a lot quicker and a bit of a mess otherwise (see the first two images).



At 3 cumulative levels in the multi-resolution reproach, a false classification does not take long to occur, so I increased that to 15 and ran that at 3 levels of dilation from the three centres for half a day. In spite of the optimisation process taking a lot longer, performance was not good, peaking well below 90% recognition rate. Although the tested dataset is not large enough to draw conclusions from, the recent experiments seem to suggest that not that a multi-scale approach on its own cannot resolve frequent recurrence of misclassifications.






In order to better understand what weakens these measures I have taken a closer look at visual GMDS output. It seems as though the scores are heightened when real (correspondent) pairs of surfaces are not yielding the correct correspondence, even after a 15-level optimisation when the data is exactly the same except the mask size (as shown in the images).
In the past, taking the best fit among all matches was tried (and watched as secondary/surrogate in all of the recent experiments in fact), but it does not perform well as a discriminant on its own. If GMDS succeeds at finding the accurate correspondence 95% of the time in these circumstances, then in this case we need to rerun GMDS several times to exceed it in terms of recognition rates. The other FMM-based method (the one I created) achieved better recognition rates than that.
In order to test the mask type and its effect on performance I ended up setting all parameters to fixed values and running very coarse-scale experiments, first on the entire face and later on a masked subset of limited size, particularly focusing on rigid parts alone.
Results were interesting in the sense that they showed that, based on GMDS as assessment criterion, smaller mask around the fixed points do not clearly and unambiguously produce better results, at least not in the case of this dataset. The assumption we had about removing the non-rigid area may have been misplaced — inherited from other work.

In the next stage I will return to fine levels to get vastly better results.
Ideally, we should initiate these high-resolution triangulations by the result we get from the lower resolution. Currently, by default, there are 9 levels, adjusted according to m, the number of sample size (300 in the latest few experiments). It’s the number of levels in the multi-resolution hierarchy. At the finest level there are typically 15999 faces and 8101 vertices (in older experiments we had just about ~2000 and in recent ones there were ~4000). A low-to-high resolution is operated by default, but it is not sufficient for evading local minima. This should explain the decrease in performance and Initialisation with lower resolution result (iteratively) should solve part of the problems.






 Filed under:
Filed under: 
 EVERAL months ago I joined Diaspora and enjoyed the good uptime of the service. The community was thriving, everyone was friendly, and the site reacted to input as one would expect. But then, just like Identi.ca, the site began having performance and uptime issues. At one point the site was down for a week. People soon lost those withdrawal symptoms and perhaps just moved on; some returned only to see sporadic operation of the site, which fairly enough is still in alpha (the software it runs is). But the bottom line is, in the early days people reviewed the site harshly for technical shortcomings. Now it’s just the really terrible uptime and low reliability. Unless this gets fixed the site is likely to lose its most ardent supporters and participants.
EVERAL months ago I joined Diaspora and enjoyed the good uptime of the service. The community was thriving, everyone was friendly, and the site reacted to input as one would expect. But then, just like Identi.ca, the site began having performance and uptime issues. At one point the site was down for a week. People soon lost those withdrawal symptoms and perhaps just moved on; some returned only to see sporadic operation of the site, which fairly enough is still in alpha (the software it runs is). But the bottom line is, in the early days people reviewed the site harshly for technical shortcomings. Now it’s just the really terrible uptime and low reliability. Unless this gets fixed the site is likely to lose its most ardent supporters and participants.
 UMAN BEINGS are a special kind of animal because we, humans, are the only ones capable of writing about animals. The inclination to distinguish between human and animal is an artificial one, a bit like saying “pork” and not “pig” and “beef” instead of “cow” (not personifying something we eat). But as humans we do have special responsibilities for those of our kind — it’s an implicit contract we share because no-one wants to be seen as potential prey of one like oneself.
UMAN BEINGS are a special kind of animal because we, humans, are the only ones capable of writing about animals. The inclination to distinguish between human and animal is an artificial one, a bit like saying “pork” and not “pig” and “beef” instead of “cow” (not personifying something we eat). But as humans we do have special responsibilities for those of our kind — it’s an implicit contract we share because no-one wants to be seen as potential prey of one like oneself. N the
N the 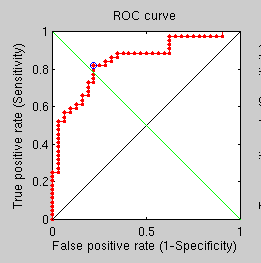


 IKE nuclear physics, good science can be exploited for bad causes. Getting access to powerful methods need not necessarily mean that this power will be benign. In fact, a lot of funding comes towards science for malicious reasons, such as war. Just look how much money gets funneled by the military industrial complex into aviation and other such research faculties/industries. There is a danger, however, which has a lot to do with how Computer Vision gets tied up with Big Brother connotations, even though Computer Vision gets used a lot to save people’s lives, e.g. in computer-guided surgeries. It would be a travesty if everyone extrapolated ideas to only show the negative uses of these ideas while ignoring the underlying science. Computer graphics is a generative science, whereas Computer Vision is more analytical. Both use models to understand nature, but one synthesises it, whereas the other converts it into information. If we are doing to assume that information collection is always a bad idea, then the World Wide Web too can be considered harmful.
IKE nuclear physics, good science can be exploited for bad causes. Getting access to powerful methods need not necessarily mean that this power will be benign. In fact, a lot of funding comes towards science for malicious reasons, such as war. Just look how much money gets funneled by the military industrial complex into aviation and other such research faculties/industries. There is a danger, however, which has a lot to do with how Computer Vision gets tied up with Big Brother connotations, even though Computer Vision gets used a lot to save people’s lives, e.g. in computer-guided surgeries. It would be a travesty if everyone extrapolated ideas to only show the negative uses of these ideas while ignoring the underlying science. Computer graphics is a generative science, whereas Computer Vision is more analytical. Both use models to understand nature, but one synthesises it, whereas the other converts it into information. If we are doing to assume that information collection is always a bad idea, then the World Wide Web too can be considered harmful. AD habits die hard. Good habits stay, so over time
AD habits die hard. Good habits stay, so over time 



 N a daily basis I must produce logs for 4 IRC channels. Over time I found more efficient ways for doing so and this post summarises some of the shortcuts and tools. It doesn’t go into specifics where these are not generalisable.
N a daily basis I must produce logs for 4 IRC channels. Over time I found more efficient ways for doing so and this post summarises some of the shortcuts and tools. It doesn’t go into specifics where these are not generalisable.