 fter persistence and a new type of mask put in place (with a little trick to penalise for miscorrespondence around the top) I have been getting good validation results again, with over 98% for the first 50 pairs I have tested (just one mistake some far). Some of the harder surface pairs have not been reached yet.
fter persistence and a new type of mask put in place (with a little trick to penalise for miscorrespondence around the top) I have been getting good validation results again, with over 98% for the first 50 pairs I have tested (just one mistake some far). Some of the harder surface pairs have not been reached yet.

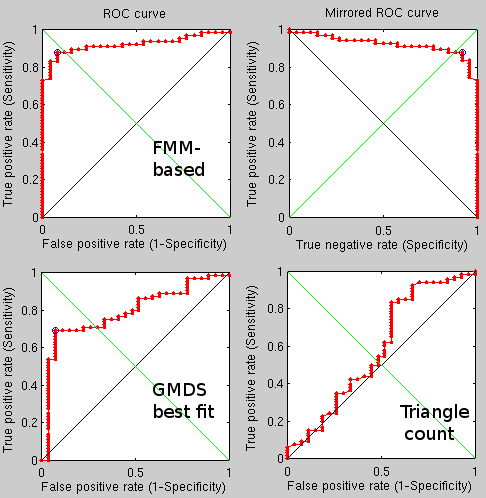
In an attempt to master GMDS as cross-identity discriminator I have further cut down the process, which now operates through a pipeline of reverse dilation, as shown in the first image beneath. The second shows a broader mask working upon false pairs and mostly failing, which is probably what we want. In terms of performance, as long as the true pairs are similar enough (some are far harder than others, e.g. expression variation), we are able to get decent results. Running this on the whole database again would not help beat results that we got around December, though. Several experimental modifications are hard to identify as means of reverting back to old versions. A lot of those were made to facilitate diffusion as a supported (surrogate) option.


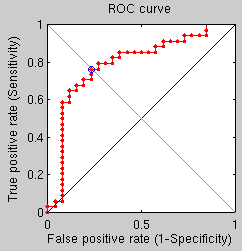
I have reduced the number of points in GMDS to just 10 because it seemed as though it would significantly speed up the process without compromising too much in terms of performance. The experiments were then run on “hard” pairs, giving verification performance of almost 90%, depending on the method used.
In an attempt to understand how well one can do with just 10 samples in GMDS (because it is faster and insensitive to small changes) I took some of the hardest classification cases and ran repeated coarse GMDS on them, reaching a success rate of only 75% or thereabouts. This falls short because we are assuming that only for false pairs will we have improper correspondence, whereas for true pairs everything will be perfect. As shown in the images produced from the same false pair, sometimes a good correspondence is found, but usually not (symbolised by white colours in the dots, e.g. in the third example from the top, on the right hand side).
The example at the very bottom shows that even for different identities a decent correspondence can be found, which gives rather low stress values.

In order to mitigate or altogether annul the effect/artifact of flipping, I have made the two surfaces asymmetric, with centres of the eyes removed because there’s too much noise there, depending where the eyes look and how open they are (in some surfaces, the eyes are deliberately moved to challenge algorithms).
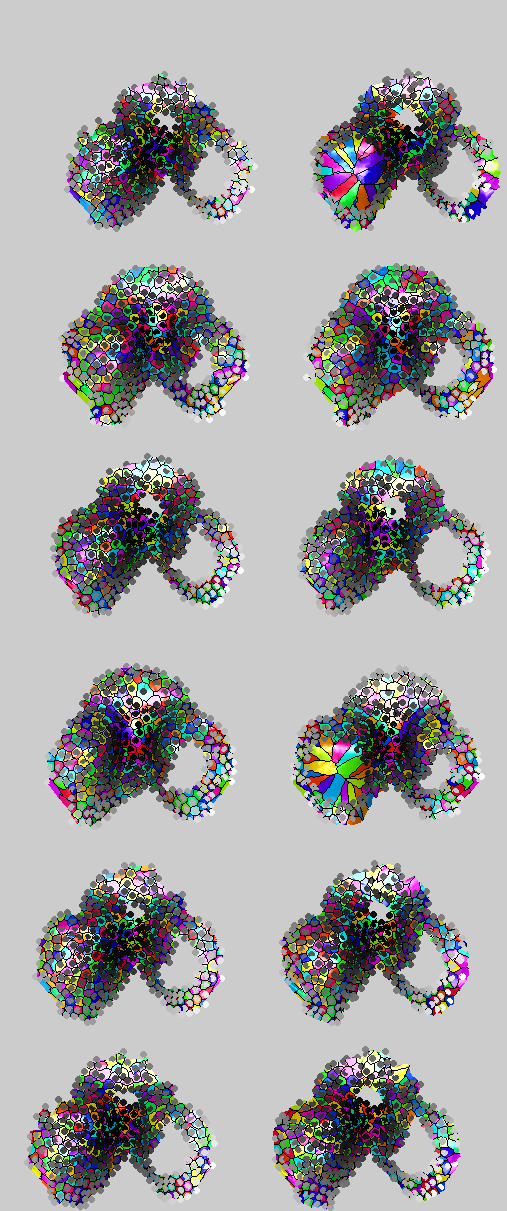
Several empirical results show that increasing the number of vertices, even doubling them, still seems not to help much in any way. So, I have isolated some difficult cases and I am trying to cut out the sources of ambiguity.






 Filed under:
Filed under:  OMORROW I shall do the eighth stage of the Mr. Fitness competition. So far I have gotten first place in almost every stage, but tomorrow’s stage is hard and I have done almost no practice towards it. It’s so much easier to just do stuff on the computer (photos below are from today and yes, I’ve stayed home all day).
OMORROW I shall do the eighth stage of the Mr. Fitness competition. So far I have gotten first place in almost every stage, but tomorrow’s stage is hard and I have done almost no practice towards it. It’s so much easier to just do stuff on the computer (photos below are from today and yes, I’ve stayed home all day).
 EVERAL years ago I wrote about
EVERAL years ago I wrote about  EOPLE often fail to understand that a troll will strive to be inflammatory so as to push for censorship, then play the “victim” card. This is one of the most effective ways for the troll to discredit its target — to claim to be suppressed and then see how far it can be pushed. The solution to this is not easy; one is to let the troll do the trolling and another is to actually censor the troll. Does anyone have good advice on the matter?
EOPLE often fail to understand that a troll will strive to be inflammatory so as to push for censorship, then play the “victim” card. This is one of the most effective ways for the troll to discredit its target — to claim to be suppressed and then see how far it can be pushed. The solution to this is not easy; one is to let the troll do the trolling and another is to actually censor the troll. Does anyone have good advice on the matter? ACK in 2004 I set up this Web log where I posted every day, and almost without a single exception (usually I posted around 3 posts per day). It was only in 2006 that I started to focus on more specific issues and developed an expertise in particular subjects. Techrights was a lot more focused than this personal blog, which has not produced about 2,000 posts.
ACK in 2004 I set up this Web log where I posted every day, and almost without a single exception (usually I posted around 3 posts per day). It was only in 2006 that I started to focus on more specific issues and developed an expertise in particular subjects. Techrights was a lot more focused than this personal blog, which has not produced about 2,000 posts.

 espite the fact that I cannot rollback to old versions of the algorithm — those that worked much better — I have run experiments on half of the entire Texas database. The performance was vastly inferior because of changes that I have made over the past couple of months.
espite the fact that I cannot rollback to old versions of the algorithm — those that worked much better — I have run experiments on half of the entire Texas database. The performance was vastly inferior because of changes that I have made over the past couple of months.





