
 EVERAL times in the past I whined about the state of the Internet. It is too susceptible to various faces of evil — something which is finally recognised at a higher level and is attributed to the way the Internet was initially conceived, engineered and set up. Blame it on Al Gore if you wish, for he is the one who “invented the Internet”.
EVERAL times in the past I whined about the state of the Internet. It is too susceptible to various faces of evil — something which is finally recognised at a higher level and is attributed to the way the Internet was initially conceived, engineered and set up. Blame it on Al Gore if you wish, for he is the one who “invented the Internet”.
My main domain continues to suffer from zombie attacks and brute-force hacking attempts, all of which are unsuccessful. Such attacks may seem like benign inconveniences when properly filtered, yet all such attempts contribute to ‘noise’. They also require a lot of work to circumvent and defeat.
If a Web page, let us say /foo/bar/ includes the word “guestbook” (especially in the page title), one may find errors in the site logs which resemble a particular pattern. These would be common sensitive addresses such as /foo/bar/addentry.php or /foo/bar//addentry.php, which indicate an attempt to spam em masse. The culprits are lazy spammers who scan a page (often a search results page) and run some scripts. The aim is to exploit widely-known vulnerabilities, which have been already patched in most cases. There are rarely open sores in Open Source, but large-scale spam continues to pose a risk and devours precious bandwidth.
As an example of spamming attempts, I find many requests that are similar to:
[Tue Jan 31 07:33:56 2006] [error] [client 69.31.80.114] File does not exist: /home/schestow/public_html/Weblog/archives/2005/07/addentry.php
These are, of course, automated attempts which are directed at pages containing the word “guestbook”. The attacks are thrown at many sites simultaneously, regardless of what software is actually used.
In other circumstances, hacking attempts involve hijacking of a content management systems or an entire Web site, which is worse than spam. These are attempts to deface, being the equivalent of a UseNet defamation or complete name mocking, crossposted for public humiliation (an example).
I used to very much worry about people’s ability to write self-derogatory blog comments, newsgroups posts, and mailing list messages ‘on behalf’ of somebody else. I saw it happening many times before. The least one can do is embrace PGP for signatures. No less. Not everyone can spot IP addresses and track them. People can nymshift without any restrictions.
If manners are the glue of on-line communities, what are the motives of such vandals? When has cracking (as opposed to “hacking”) become popular? The motives must be a boost to ego and clan vanity (or “klan” rather). Sometimes, Web sites are captured and then re-direct to steal ranks which are accredited by search engines.
What have I done on the matter? Not much so far, but I found a neat solution to the Windows zombies. Many common attempts to hack are being redirectd to this page rel="nofollow", to which I referred in this previous blog item. Errors and attempts to hack can be suppressed using re-directions on common URL‘s, which characterise vulnerable components or exploitation of script for mass-mailing or spam. All in all, after much work, Web malice has been lowered to a manageable level.






 Filed under:
Filed under: 
 FTER Slashdot’s transition to proper CSS-based layout (it used to be heavily based on tables), a contest is run to select the new, permanent site design. Here are some of the latest design contenders. Some of these designs are included as actual Web pages, whereas others are appended as PNG-formatted screenshots. Shown above is the Slashdot front page as of April 1st this year.
FTER Slashdot’s transition to proper CSS-based layout (it used to be heavily based on tables), a contest is run to select the new, permanent site design. Here are some of the latest design contenders. Some of these designs are included as actual Web pages, whereas others are appended as PNG-formatted screenshots. Shown above is the Slashdot front page as of April 1st this year.
 was innocently browsing the Internet this morning. By serendipity, I then arrived at a page where Google boast their contributions to Open Source software through funding (
was innocently browsing the Internet this morning. By serendipity, I then arrived at a page where Google boast their contributions to Open Source software through funding ( NCE again, a timely article that covers
NCE again, a timely article that covers 
 HIS morning I found (and began playing with) a GPL‘d newsgroups statistics tool (
HIS morning I found (and began playing with) a GPL‘d newsgroups statistics tool (
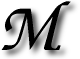 SN, AOL and
SN, AOL and 