Possible Project: Computer Vision on Android
 Filed under:
Filed under:  few years ago the DARPA Grand Challenge explored that scarcely understood potential of autonomous vehicle navigation with on-board, non-remote computer/s and a fixed number of viewpoints (upper bound on apertures, processing power, et cetera). This received a great deal of press coverage owing to public interest, commercial appeal, and the general underlying novelty. While the outcome was promising, not many people are able to afford the equipment at hand. With mobile devices proliferating, semi-autonomous or computer-aided driving becomes an appealing option, just as surgeries are increasingly involving assistance from computers (c/f MICCAI as a conference). This trend continues as confidence in the available systems increases and their practical use is already explored in particular hospitals where human life is at stake.
few years ago the DARPA Grand Challenge explored that scarcely understood potential of autonomous vehicle navigation with on-board, non-remote computer/s and a fixed number of viewpoints (upper bound on apertures, processing power, et cetera). This received a great deal of press coverage owing to public interest, commercial appeal, and the general underlying novelty. While the outcome was promising, not many people are able to afford the equipment at hand. With mobile devices proliferating, semi-autonomous or computer-aided driving becomes an appealing option, just as surgeries are increasingly involving assistance from computers (c/f MICCAI as a conference). This trend continues as confidence in the available systems increases and their practical use is already explored in particular hospitals where human life is at stake.
Road regulations currently limit the level to which computers are able to control vehicles, but in the US those regulations are subjected to constant lobbying. Many devices utilise GPS-obtained coordinates, but very few exploit computer vision methods to recognise obstacles that are observed natively rather than derived from a map (top-down). A comprehensive search around the Android repository reveals very little work on computer vision among popular applications. Processor limitations, complexity, and lack of consistency (e.g. among screen sizes and camera resolution) pose challenges, but that oughtn’t excuse this computer vision ‘drought’. A lot of code can be conveniently ported to Dalvik.
In order to explore the space of existing work and products, with special emphasis on mobile applications, I have begun looking at what’s available for navigation bar stereovision (as it would require multiple phones or a detached extra camera for good enough triangulation). Tablets and phones make built-in cameras more ubiquitous, alas their full potential is rarely realised, e.g. when docked upon a panel in a car with a high-resolution, high capture rate (framerate) camera.
According to Wikipedia, “Mobileye is a technology company that focuses on the development of vision-based Advanced Driver Assistance Systems” and this system is geared towards providing the user with car navigation capabilities that are autonomous and rely only on a single camera, such as the one many phones have. Functionality is said to include Vehicle Detection, Forward Collision Warning, Headway Monitoring & Warning, Lane Departure Warning and Lane Keeping / Lane Guidance, NHTSA LDW and FCW, Pedestrian Detection, Traffic Sign Recognition, and Intelligent Headlight Control. The company received over $100 million in investment as the computer-guided navigation market seems to be growing rapidly. A smartphone application is made available by Mobileye, with a demo version available for Android. “Although the Mobileye IHC icon will appear on the application, it requires additional hardware during installation,” their Web site says. The reviews by users are largely positively (demo version, 1.0, updated and release January 5th, 2012).
The collective of Android apps for car navigation suggests that it’s a crowded space, but a lot uses GPS and not computer vision.
The video “Motorola Droid Car Mount Video Camera Test” shows the sort of sequence which needs to be dealt with. Lacking hardware acceleration it would be hard to process frames fast enough (maybe the difference between them would be more easily manageable). Response time for driving must avert lag. It’s the same with voice recognition on phones as it’s rarely satisfactory in real-time mode. Galaxy II, for example, takes a couple of seconds to process a couple of words despite having some very cutting-edge hardware.






 N OUR pursuit of a similarity measure for anatomical surfaces (biomedical or otherwise external to one’s body), integration over the dot product between the normals is considered. This is a powerful correlation measure between aligned surfaces, i.e. integral |<normal_1,normal_2>| delta area. The higher the integral, the higher the correlation.
N OUR pursuit of a similarity measure for anatomical surfaces (biomedical or otherwise external to one’s body), integration over the dot product between the normals is considered. This is a powerful correlation measure between aligned surfaces, i.e. integral |<normal_1,normal_2>| delta area. The higher the integral, the higher the correlation.







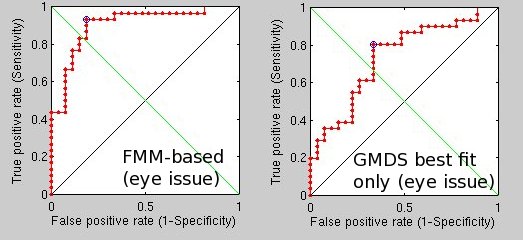
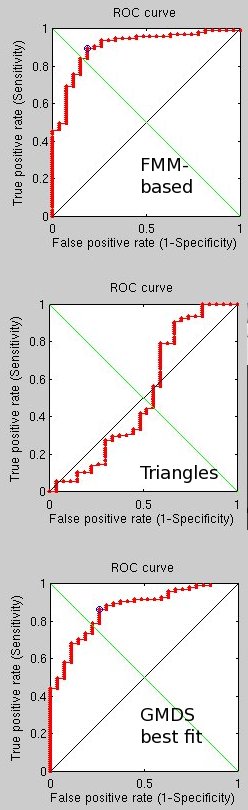
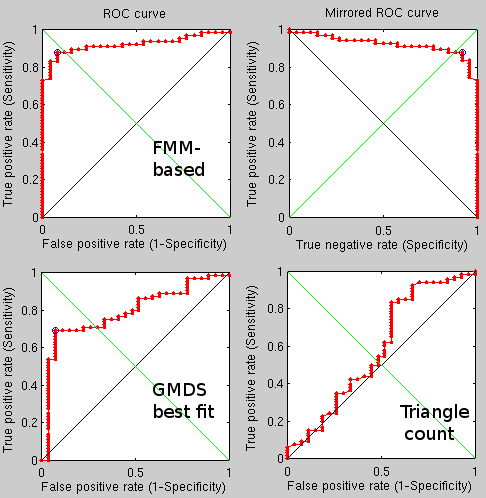
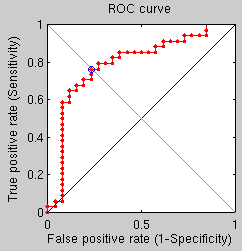
 sing a more brute force approach which takes into account a broader stochastic process, performance seems to have improved to the point where for 50 pairs (100 images) there are just 2 mistakes using the FMM-based approach and 1 using the triangles counting approach. This seems to have some real potential, even though it is slow for the time being (partly because 4 methods are being tested at the same time, including two GMDS-based approaches).
sing a more brute force approach which takes into account a broader stochastic process, performance seems to have improved to the point where for 50 pairs (100 images) there are just 2 mistakes using the FMM-based approach and 1 using the triangles counting approach. This seems to have some real potential, even though it is slow for the time being (partly because 4 methods are being tested at the same time, including two GMDS-based approaches). 

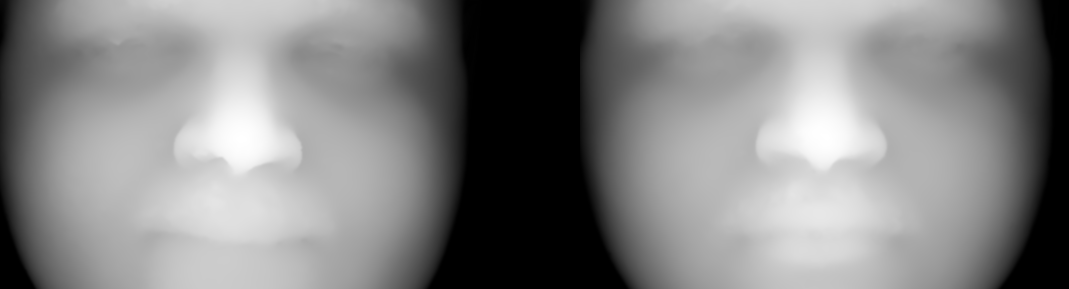
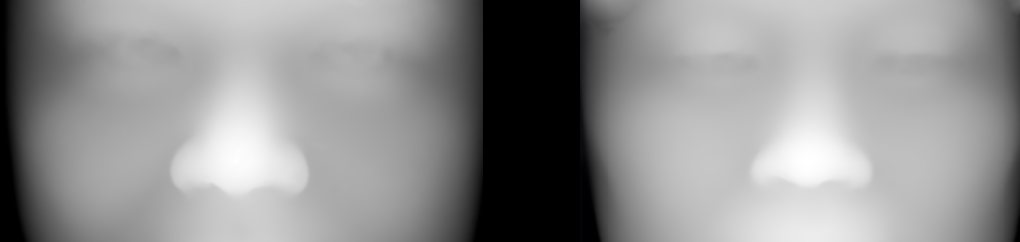
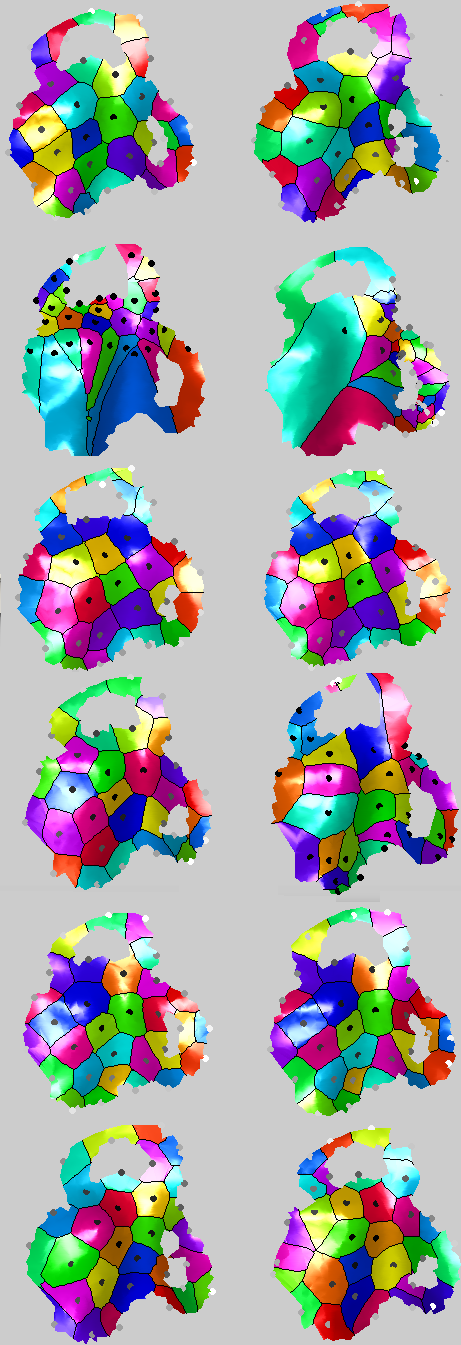
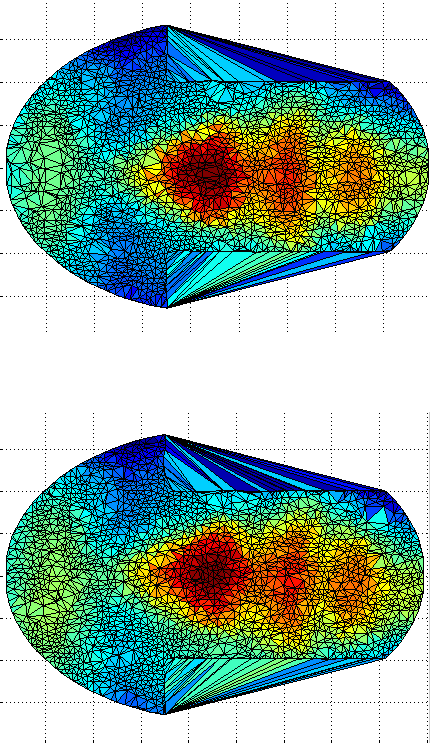


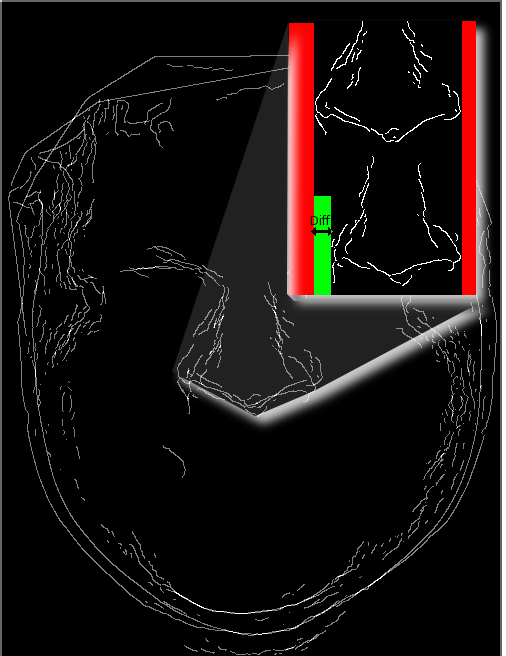
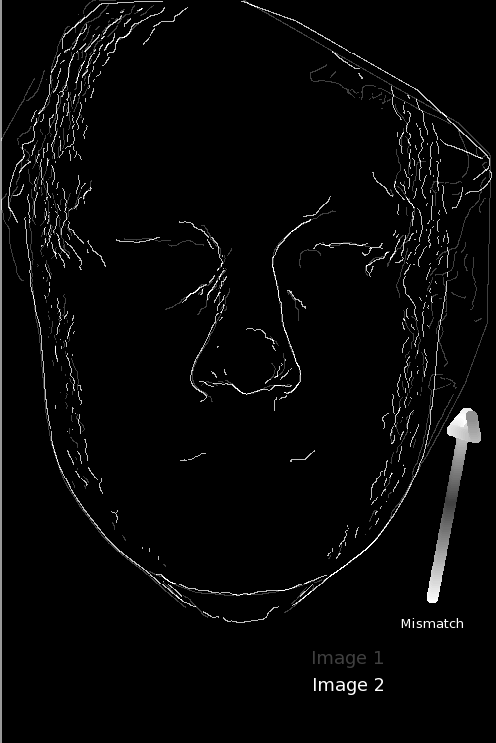
 he latest batch of experiments looked at how one might cope with a mask closer than usual to the eye’s centre. I used harder pairs.
he latest batch of experiments looked at how one might cope with a mask closer than usual to the eye’s centre. I used harder pairs.