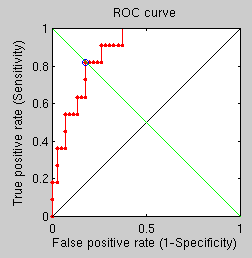
GMDS vs Other FMM-based Measures
 Filed under:
Filed under:  N the previous post on this subject we looked at the masks used in a GMDS pipeline tailored for recognition purposes. The question now is, what would be a constructive way to progress from the conclusion?
N the previous post on this subject we looked at the masks used in a GMDS pipeline tailored for recognition purposes. The question now is, what would be a constructive way to progress from the conclusion?
Well, the goal is to beat the competition and do so with methods of a particular kind — the kind we advocate — which seems achievable but requires a lot of tinkering, seeing where and how mistakes can be resolved/avoided.
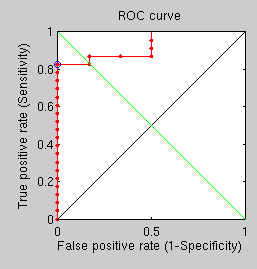
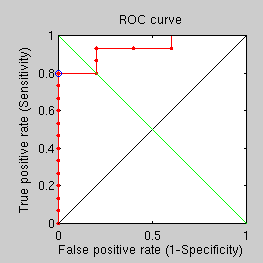
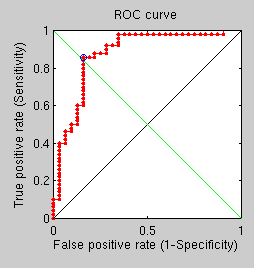
An additional experiment, taking about a day to complete, shows not much promise. Its goal is simply to compare the performance of GMDS with the new Fast Marching Methods-based measures (faster) when all parameters are kept consistent across runs. With many rings, many points, and many vertices, recongition performance is relatively poor because of the hard dataset, as demonstrated by the ROC curve. The point to note though is that in hard cases GMDS is outperformed by the other approach. One question is, are there any measurable quantifies (other than stress) resulting from GMDS and capable of assessing similarity?
GMDS multiple runs
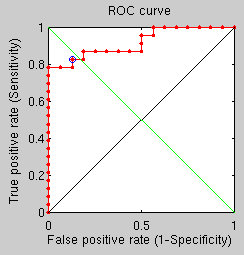
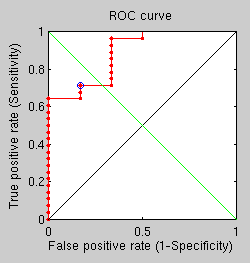
FMM-based
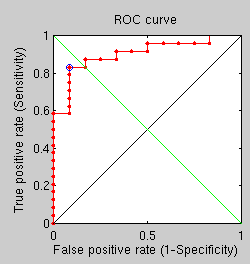
There are some additional results from the last set of shallow, comparative tests. By applying the same experiment’s parameters to test an antiquated triangle-counting approach and a best fit GMDS approach (rather than average over multiple runs) we get two more ROC curves.
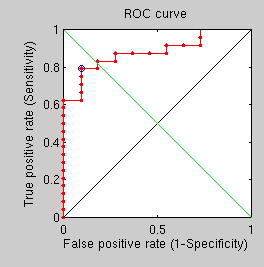
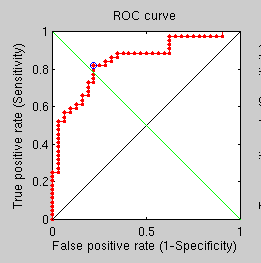
Triangle counting
GMDS best fit

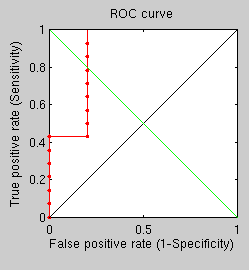
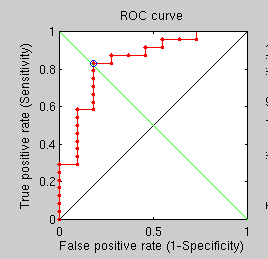
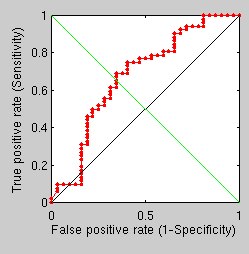
Finally, using this same difficult set (where problematic cases are included) we get a ROC curve for the standard GMDS approach.
Simple GMDS
In GMDS one could either work with and L2 norm (which is what we do right now) or Linfty. In fact, if one takes the log of the distances and apply GMDS, one does, in a sense Lipschitz embedding. The diffusion distances could also be used within the GMDS framework. In fact, with better interpolation properties, one can interpolate the eigenfunction before integrating the distance itself…
I spoke to a colleague about Linfty and I now attempt to compile it on GNU/Linux (not done before). It would be interesting to know if GMDS been tested where D is computed based on spectral properties (not as geodesics). There an IJVC paper with Sapiro in which this is done; in it, the authors are also finding symmetries that way.
 HIS post is part of a series that explores the potential of comparing surfaces using GMDS, or generalised multidimensional scaling.
HIS post is part of a series that explores the potential of comparing surfaces using GMDS, or generalised multidimensional scaling.









 AD habits die hard. Good habits stay, so over time
AD habits die hard. Good habits stay, so over time 


 EGACY of one’s life may typically matter to a person when death is near. That’s partly because last/recent memories persist better than old ones. Legacy is also what remains in visibility after a person departs from this world, having first emerged in it through conception. But legacy need not be associated with depressing things such as being deceased. Legacy throughout one’s life can be seen as the work that’s left to have impact when one moves from one area to another, from one field of work to another.
EGACY of one’s life may typically matter to a person when death is near. That’s partly because last/recent memories persist better than old ones. Legacy is also what remains in visibility after a person departs from this world, having first emerged in it through conception. But legacy need not be associated with depressing things such as being deceased. Legacy throughout one’s life can be seen as the work that’s left to have impact when one moves from one area to another, from one field of work to another. S natural succession to the previous experiments, I compromise speed and increase the number of points in GMDS from 10 to 50, hoping to see performance improved noticeably. So far, based on results that are coming out, no classification mistakes are being made, but more pairs need to be tested overnight before meaningful conclusions can be drawn.
S natural succession to the previous experiments, I compromise speed and increase the number of points in GMDS from 10 to 50, hoping to see performance improved noticeably. So far, based on results that are coming out, no classification mistakes are being made, but more pairs need to be tested overnight before meaningful conclusions can be drawn.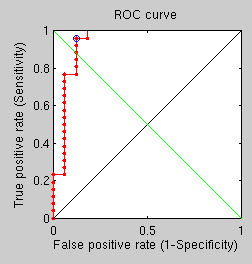

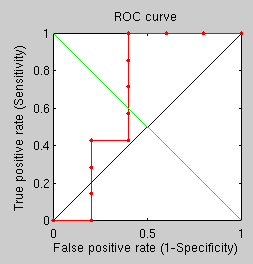

 OLLOWING this
OLLOWING this