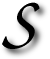 itemaps are probably the most crucial pages in all Web sites. They might not be most helpful to human visitors, but they greatly assist crawlers, thereby attracting, promoting and inviting more traffic from search engines. Site maps can be perceived as ‘crawling maps’, regardless of how shallow or deep they are. These maps not just the spine, but possibly the entire skeleton of complex Web sites where crawling will take a huge number of distinct routes through pages.
itemaps are probably the most crucial pages in all Web sites. They might not be most helpful to human visitors, but they greatly assist crawlers, thereby attracting, promoting and inviting more traffic from search engines. Site maps can be perceived as ‘crawling maps’, regardless of how shallow or deep they are. These maps not just the spine, but possibly the entire skeleton of complex Web sites where crawling will take a huge number of distinct routes through pages.
 Google have recently introduced RSS sitemaps. This means that new site content will be appended to the map whose form is a long aggregated feed, i.e. links with minimal content and without unimportant media and layout detail. This move by Google encouraged many Webmasters to go on the RSS wagon and XML their Web sites. This benefits Google in a variety of ways. First of all, there is a clear pairing between content and dates. If the site delivers timely news, this will become a significant factor. Secondly, as any site is described fully by its map, there is no need for repeated crawling. There are significant savings in terms of bandwidth, which appear to allow search engines to crawl a sparser portion of the Web, as well as reduce the burden on Web servers, whose load involves a great deal of pages being served to crawlers or robots.
Google have recently introduced RSS sitemaps. This means that new site content will be appended to the map whose form is a long aggregated feed, i.e. links with minimal content and without unimportant media and layout detail. This move by Google encouraged many Webmasters to go on the RSS wagon and XML their Web sites. This benefits Google in a variety of ways. First of all, there is a clear pairing between content and dates. If the site delivers timely news, this will become a significant factor. Secondly, as any site is described fully by its map, there is no need for repeated crawling. There are significant savings in terms of bandwidth, which appear to allow search engines to crawl a sparser portion of the Web, as well as reduce the burden on Web servers, whose load involves a great deal of pages being served to crawlers or robots.
There are hidden dangers in moving towards RSS sitemaps. Typical HTML/XHTML/other site maps get neglected as they are laborious to maintain and as time goes by they may appear redundant, much like an older generation of pages that have gone completely out of date. One of the worrying implications is that opponents — in this particular case MSN and Yahoo predominantly — get ‘robbed’ of the true, old-styled site maps, which are conceded altogether or simply neglected in favour of RSS sitemaps. Therefore, they must follow suit and take advantage of the public RSS site maps, just as Google did. They might need to woo Webmasters and get those sitemap submitted to them as well. Is it going to be an easy task? Probably not, especially while Google’s impact is by far superior.
The phenomenon above is the introduction and absorbance of new technologies by force. Google are forcing, not malevolently though, trends of crawling and push for methods to change. Microsoft exhibited some similar behaviour by introducing new elements to HTML without consent from the community. They incorporated these element into Internet Explorer; they considered the Internet to be a source to serve Internet Explorer rather than the reverse, whereby the Web is open and accessible to all. By doing so, Microsoft encouraged Web developers to construct Web pages that work exclusively under Internet Explorer and slowly killed their main opponent: Netscape Navigator. But that is all history as Internet Explorer (version 6) lags behind Opera, Firefox and arguably behind Safari too.
In practical terms, do RSS sitemaps lead to any gains? We have discussed this issue to death at the primary SEO-related newsgroup. Borek expressed his skepticism about Google sitemaps:
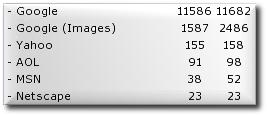
So far Google just fetches my sitemaps 4 times a day. One site is PR3 5 months old, second is PR2 several years old, redesigned in June. No signs of crawl on either (and there are not spidered pages on both sites).
The bottom line, from my point-of-view, is that for news-delivering sites, RSS sitemaps provide a good opportunity to conquer valuable SERP‘s very quickly. For most standard sites with a decent amount of bandwidth to spare, RSS sitemaps appear like an overkill, even when HTML to XML implementation are virtually available ‘off-the-shelf’. RSS sitemaps may also be valuable for blogs where the nature of publication is linear rather than hierarchical or lateral.
Other related threads on the topic:
Related News: Google to Patent Ads in Feeds






 Filed under:
Filed under: 

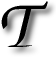 HERE appears to have been a recent growth in PageRank and SEO analysis tools. Such tools have an on-line front-end (interface) so they are easily and readily accessible. Here is a short survey of tools that not only have I used, but I can also confirm are valuable:
HERE appears to have been a recent growth in PageRank and SEO analysis tools. Such tools have an on-line front-end (interface) so they are easily and readily accessible. Here is a short survey of tools that not only have I used, but I can also confirm are valuable:
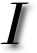 have recently become aware of highly dirty practices, which sometimes get used by malovalent SEO‘s.
have recently become aware of highly dirty practices, which sometimes get used by malovalent SEO‘s.  oogle’s PageRank mechanism refelects on popularity estimates in most engines and directories, which presently adopt similar ranking methods that are based on
oogle’s PageRank mechanism refelects on popularity estimates in most engines and directories, which presently adopt similar ranking methods that are based on 
 Content spam grows worryingly fast. This new type of spam shows its face in a form which is different from spam that we very well know as uninvited E-mail. Such spam is placed on the Web and later infiltrates search engine results pages (SERP’s). If you recently came across a page full of links and ads that did not provide useful information, you would probably understand what content spam is.
Content spam grows worryingly fast. This new type of spam shows its face in a form which is different from spam that we very well know as uninvited E-mail. Such spam is placed on the Web and later infiltrates search engine results pages (SERP’s). If you recently came across a page full of links and ads that did not provide useful information, you would probably understand what content spam is.