





Our Drupal Interview With Jeffrey A. “jam” McGuire, Open Source Evangelist at Acquia
 Filed under:
Filed under:  ux Machines has run using Drupal for nearly a decade (the site is older than a decade) and we recently had the pleasure of speaking with Jeffrey A. “jam” McGuire, Open Source Evangelist at Acquia, the key company behind Drupal (which the founder of Drupal is a part of). The questions and answers below are relevant to many whose Web sites depend on Drupal.
ux Machines has run using Drupal for nearly a decade (the site is older than a decade) and we recently had the pleasure of speaking with Jeffrey A. “jam” McGuire, Open Source Evangelist at Acquia, the key company behind Drupal (which the founder of Drupal is a part of). The questions and answers below are relevant to many whose Web sites depend on Drupal.
1) What is the expected delivery date for Drupal 8 (to developers) and what will be a good point for Drupal 6 and 7 sites to advance to it?
Drupal 8.0.0 beta 1 came out on October 1, 2014, during DrupalCon Amsterdam. It’s a little early for designers to port their themes, good documentation to be written, or translators to finalise the Drupal interface in their language – some things are still too fluid. For coders and site builders, however, it’s a great time to familiarise yourself with the new system and start porting your contributed modules. Read this post by Drupal Project Lead, Dries Buytaert; it more thoroughly describes who and what the beta releases are and aren’t good for: “Betas are good testing targets for developers and site builders who are comfortable reporting (and where possible, fixing) their own bugs, and who are prepared to rebuild their test sites from scratch when necessary. Beta releases are not recommended for non-technical users, nor for production websites.”
With a full Release Candidate or 8.0.0 release on the cards for some time in 2015, now is the perfect time to start planning and preparing your sites for the upgrade to Drupal 8. Prolific Drupal contributor Dave Reid gave an excellent session at DrupalCon Amsterdam, “Future-proof your Drupal 7 Site”, in which he outlines a number of well-established best practices in Drupal 7 that will help you have a smooth migration when it is time – as well as a number of deprecated modules and practices to avoid.
2) What is the importance of maintaining API and module compatibility in future versions of Drupal and how does Acquia balance that with innovation that may necessitate new/alternative hooks and functions?
The Drupal community, which is not maintained or directed by Acquia or any company, has always chosen innovation over backward compatibility. Modules and APIs of one version have never had to be compatible with other versions. The new point-release system that will be used from Drupal 8.0.0 onwards – along with new thinking among core contributors and the broader community – may change this in future. There has been discussion, for example, of having APIs valid over two releases, guaranteeing that a Drupal 8 module would still work in Drupal 9 and that a Drupal 9 module would work in Drupal 10. Another possibility is that this all may be obviated in the future as moves toward broad intercompatibility in PHP lead to the creation of PHP libraries with Drupal implementations rather than purely Drupal modules.
3) Which Free/libre software project do you consider to be the biggest competitor of Drupal?
The “big three” FOSS CMSs – Drupal, WordPress, and Joomla! – seem to have settled into roughly defined niches. There is no hard and fast rule to this, but WordPress runs many smaller blogs and simpler sites; Joomla! projects fall into the small to medium range; and Drupal projects are generally medium to large to huge and complex. Many tech people with vested interests in one camp or another may identify another project as “frenemies” and compete with these technologies when bidding for clients, but the overall climate between the various PHP and open source projects is friendly and open. Drupal is one of the largest free/libre projects out there and doesn’t compete with other major projects like Apache, Linux, Gnome, KDE, or MySQL. Drupal runs most commonly on the LAMP stack and couldn’t exist or work at all without these supporting free and open source technologies.
NB – I use the term “open source” as synonymous shorthand for “FOSS, Free and Open Source Software, and/or Free/libre software”.
4) Which program — proprietary or Free/libre software — is deemed the biggest growth opportunity for Drupal?
Frankly, all things PHP. Drupal’s biggest growth opportunity at present is its role as an innovator and “meta-project” in the current “PHP Renaissance”. While fragmented at times in the past, the broader PHP community is now rallying around common goals and standards that allow for extensive compatibility and interoperability between projects. For the upcoming Drupal 8 release, the project has adopted object-oriented coding, several components from the Symfony2 framework, a more up-to-date minimum version of PHP (5.4 as of October 2014), and an extensive selection of external libraries.
On the one hand, Drupal being at the heart of the action in PHP-Land allows it and its community of innovators to make a more direct impact and spread its influence. On the other hand, it is now also able to attract even more developers from a variety of backgrounds to use and further develop Drupal. A Symfony developer (who has had a client website running on Drupal 8 since summer 2014) told me that looking under the hood in Drupal 8, “felt very familiar, like looking at a dialect of Symfony code.”
NB – I use the term “open source” as synonymous shorthand for “FOSS, Free and Open Source Software, and/or Free/libre software”.
5) To what degree did Drupal succeed owing to the fact that Drupal and all contributed files are licensed under the GNU GPL (version 2 or 3)?
“Building on the shoulders of giants” is a common thread in free and open source software. The GPL licenses clearly promote a culture of mutual sharing. This certainly applies to Drupal, where I can count on huge advantages thanks to benefitting from more than twelve years of development, 100k+ active users, running something like 2% of the Web for thousands of businesses, and millions of hours of coding and best practices by tens of thousands of active developers. Our code being GPL-licensed and collected in a central repository on Drupal.org has allowed us to build upon the strengths of each other’s work in a Darwinian environment (”bad code dies or gets fixed” – Jeff Eaton) where the best code rises to the top and becomes even better thanks to the attention of thousands of site owners and developers. The same repository has contributed to a reputation economy where bad actors and dubious or dangerous code has little chance of survival.
The GPL 2 is business friendly in that the license specifically allows for commercial activity and has been court tested. As a result, there is very little legal ambiguity in adopting GPL-licensed code. It also makes clear cases for when code needs to be shared as open source and when it doesn’t (allowing for sites to use Drupal but still have “proprietary” code). The so-called “Web Services Loophole” caused some controversy and discussion, but also opened the way to SaaS products being built on free/libre GPL code. Drupal Project Lead Dries Buytaert explained this back in 2006 (read the full post here):
“The General Public License 2 (GPL 2), mandates that all modifications also be distributed under the GPL. But when you are providing a service through the web using GPL’ed software like Drupal, you are not actually distributing the software. You are providing access to the software. Thus, a way to make money with Drupal is to sell access to a web service built on top of Drupal. This is commonly referred to as the web services loophole.”
Business models remain challenging in a GPL world; nothing is stopping me from selling you GPL code, but nothing is stopping you from passing it on to anyone else either. App stores, for example, are next to impossible to realise under these conditions. Most Drupal businesses are focused on value add services like site building, auditing and consulting of various kinds, hosting, and so on, with a few creating SaaS or PaaS offerings of one kind or another.
NB – I use the term “open source” as synonymous shorthand for “FOSS, Free and Open Source Software, and/or Free/libre software”.
6) What role do companies that build, maintain and support Drupal sites play in Acquia’s growth and in Drupal’s growth?
Acquia was the first company to offer SLA-based commercial support for Drupal (a Service Level Agreement essentially says, “In return for your subscription, Acquia promises to respond to your problems within a certain time and in a certain manner”). The specifics of response time and action vary according to the level of subscription, but these allowed a new category of customer to adopt Drupal: The Enterprise.
Enterprise adoption – think Whitehouse.gov, Warner Music, NBC Universal, Johnson & Johnson – of Drupal resulted in increased awareness and therefore even further increased adoption (and improvement) of the platform over time. Everyone who delivers a successful Drupal project for happy clients improves Drupal for everyone else involved. The more innovative projects there are, the more innovation flows back into our codebase. The more happy customers there are, the more likely their peers are to adopt Drupal, too. Finally, the open source advantage also comes into play: it behooves Drupal service providers to give the best possible service and deliver the highest-quality sites and results. If they don’t, there is no vendor lock-in and being open source at scale also means you can find another qualified Drupal business to work with if it becomes necessary. Acquia and the whole, large Drupal vendor ecosystem simultaneously compete, cooperatively grow the project (in code and happy customer advocates), and act as each other’s safety net and guarantors.
NB – I use the term “open source” as synonymous shorthand for “FOSS, Free and Open Source Software, and/or Free/libre software”.
7) How does Acquia manage and coordinate the disclosure of security vulnerabilities, such as the one disclosed on October 15th?
Acquia as an organisation is an active, contributing member of the Drupal community and it adheres strictly to the Drupal project’s security practices and guidelines, including the Drupal project’s strict procedure for reporting security issues. Many of Acquia’s technical employees are themselves active Drupal contributors; as of October 2014, ten expert Acquians also belong to the Drupal Security Team. Acquia also works closely with other service providers, whether competitors or partners, in the best interests of all of us who use and work with Drupal. This blog post, “Shields Up!”, by Moshe Weizman explains how Acquia, in cooperation with the Drupal Security Team and some other Drupal hosting companies, dealt with the recent “Drupalgeddon” security vulnerability.
 y experience patching Drupal sites is years old and my general ‘policy’ (habit) is to not upgrade unless or until there is a severe security issue. It’s the same with WordPress, which I’ve been patching in several sites for over a decade. Issues like role escalation are not serious if you trust fellow users (authors) or if you are the sole user. In the case of some agencies that use Drupal, it might be safe to say that the risk introduced by change to code outweighs the safety because as far as one can tell, visitors of such sites do not even register for a username. All users are generally quite trusted and they work closely (one must have checked the complete list to be absolutely sure). There is also ‘paper trail’ of who does what, so if one was to exploit a bug internally, e.g. to do something s/he is not authorised to do, it would be recorded, which in itself acts as a deterrent.
y experience patching Drupal sites is years old and my general ‘policy’ (habit) is to not upgrade unless or until there is a severe security issue. It’s the same with WordPress, which I’ve been patching in several sites for over a decade. Issues like role escalation are not serious if you trust fellow users (authors) or if you are the sole user. In the case of some agencies that use Drupal, it might be safe to say that the risk introduced by change to code outweighs the safety because as far as one can tell, visitors of such sites do not even register for a username. All users are generally quite trusted and they work closely (one must have checked the complete list to be absolutely sure). There is also ‘paper trail’ of who does what, so if one was to exploit a bug internally, e.g. to do something s/he is not authorised to do, it would be recorded, which in itself acts as a deterrent.
 ccasionally it is needed to gain access to sites that are behind firewall/s and also necessary to install software on them. This is when the graphical front ends may ‘break’ (refuse to work as expected), either because Drupal cannot access the outside world or because the outside world cannot access the Drupal instance.
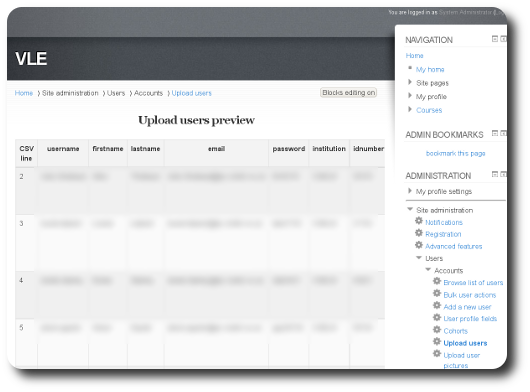
ccasionally it is needed to gain access to sites that are behind firewall/s and also necessary to install software on them. This is when the graphical front ends may ‘break’ (refuse to work as expected), either because Drupal cannot access the outside world or because the outside world cannot access the Drupal instance.  rovided one stores data in a format which is importable into Moodle (comma-separated list with specific data fields), a lot can be achieved very rapidly, making a migration to this powerful Free/libre software VLE rather painless. After some hours of work on a test site I decided to share my lessons so that others can benefit. In the spirit of sharing I will also take note of common errors that may come up and how to overcome them. If data export from an old VLE system is not consistent with the requirements of Moodle, then the migration may not be so simple. It may require several iterations.
rovided one stores data in a format which is importable into Moodle (comma-separated list with specific data fields), a lot can be achieved very rapidly, making a migration to this powerful Free/libre software VLE rather painless. After some hours of work on a test site I decided to share my lessons so that others can benefit. In the spirit of sharing I will also take note of common errors that may come up and how to overcome them. If data export from an old VLE system is not consistent with the requirements of Moodle, then the migration may not be so simple. It may require several iterations.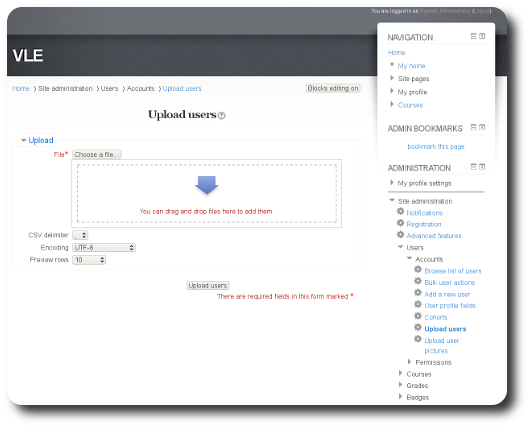








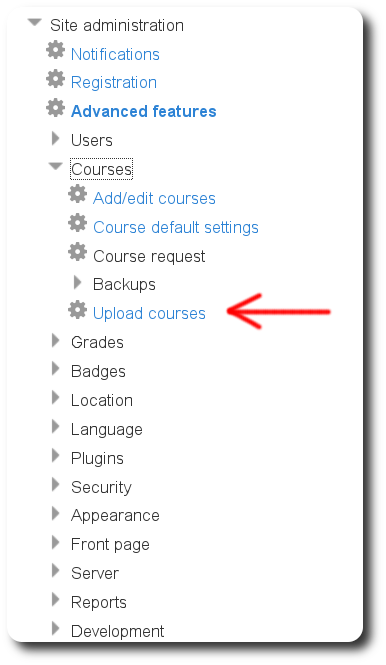

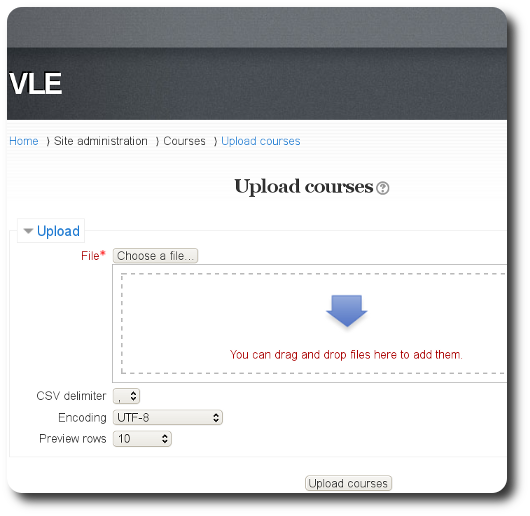

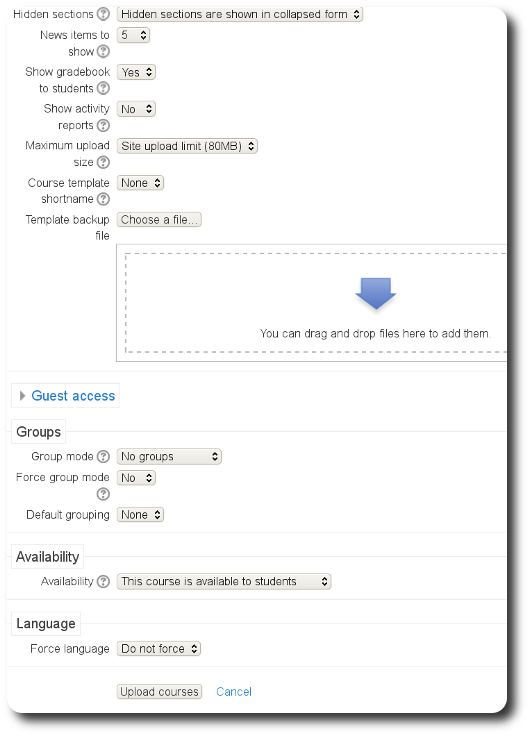
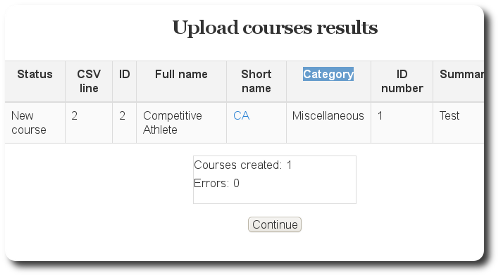









 new site I’ve launched,
new site I’ve launched,