 oogle knows precisely what you search for and keeps a record of it indefinitely. If you have a Google account, it also knows all YouTube videos you watch (how long, how many times) and many Web pages you visit (with AdSense, YouTube
oogle knows precisely what you search for and keeps a record of it indefinitely. If you have a Google account, it also knows all YouTube videos you watch (how long, how many times) and many Web pages you visit (with AdSense, YouTube embed, etc.). Never mind PageRank, Feedburner, etc. It knows your real identity now. The PATRIOT ACT (and the likes of it) lets governments access this data, too, so it’s not a purely corporate issue anymore. Lawyers and thugs turn up at the scene. There is nothing for Web users to gain from it, no matter the propaganda about “terrorists” and “pedophiles”. It’s sickening to see how lightly privacy is taken by those whom we supposedly elect.
When Google started requiring that people sign up to access a lot of its stuff (with a verified E-mail address) it was no longer just playing dice with IP addresses. Google Plus was a step further, which drove me to other search engines. Sometimes people have a common name, such as John Wilcox. By offering Google Profiles/Plus Google is able to discern one from another, plus pair it with an E-mail address. They even know how you navigate through Google StreetView and Maps. Google may also have copies of all your mails which you sent to people in GMail (certainly all of it if you use GMail). People tend to forget all of this. And this data is not being destroyed. Some is used for marketing and Google openly admits many government requests for people’s data all around the world (Google complies without a fight and without informing those affected). Transparency through statistics hardly makes the practice benign.
Do you still use Google? You probably oughtn’t, except when there is no other choice. Consider accessing YouTube from other devices without a cookie. Wherever Google is going, I don’t like it. And a lot of people forget that it’s dominantly proprietary, so I hardly care it it’s “not Microsoft” or “not Apple”. Even Android is becoming a little too creepy on the privacy side (e.g. its browser which phones home with location and usage data). Canonical takes a lesson from this business model of Google and now turns Ubuntu into spyware. I spoke to Richard Stallman in recent days. He will soon write about this topic. As always, Stallman had good foresight when it comes to privacy on the Net.
“Privacy protects us from abuses by those in power, even if we’re doing nothing wrong at the time of surveillance.”
–Bruce Schneier






 Filed under:
Filed under: 
 lot of people easily fall for the flawed argument that if you don’t do anything wrong, then you don’t have anything to hide. “Metadata” belongs to the flawed argument that if you don’t know the contents of a conversation, then it’s not violating a person’s privacy. I decided to put some hypothetical history to refute these myths.
lot of people easily fall for the flawed argument that if you don’t do anything wrong, then you don’t have anything to hide. “Metadata” belongs to the flawed argument that if you don’t know the contents of a conversation, then it’s not violating a person’s privacy. I decided to put some hypothetical history to refute these myths.
 F YOU are not worried about what you search for and how you surf the Web,
F YOU are not worried about what you search for and how you surf the Web, 
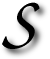 udden change in plans and improvement of research direction leads me to the exploration of MRI tagging, which proves to be difficult when one tries to actually find raw data to work with, not information about it. In the coming days I plan to prepare a post explaining to people where they can obtain tagged data of the brain and the heart (trying to help others solve the problem which occupies many hours of my time). The Internet is extremely mature when it comes to sharing of text and sometimes even audio and film, copyright being an obvious barrier. When it comes to medical data, however, it is another story altogether, even if it’s totally anonymised. Personally, I’ve put 3-D scans of my brain on this Web site, hoping to provide people with the sort of data I sometimes struggle to get a hold of.
udden change in plans and improvement of research direction leads me to the exploration of MRI tagging, which proves to be difficult when one tries to actually find raw data to work with, not information about it. In the coming days I plan to prepare a post explaining to people where they can obtain tagged data of the brain and the heart (trying to help others solve the problem which occupies many hours of my time). The Internet is extremely mature when it comes to sharing of text and sometimes even audio and film, copyright being an obvious barrier. When it comes to medical data, however, it is another story altogether, even if it’s totally anonymised. Personally, I’ve put 3-D scans of my brain on this Web site, hoping to provide people with the sort of data I sometimes struggle to get a hold of.
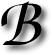 ACK when I communicated with Google, I came to realise that they have engineers whose sole/main purpose was to ensure the site stays online at all times. A few days ago I had another odd realisation, but perhaps a very obvious one. To search engines, downtimes are a hugely damaging thing. If people are unable to search for something immediately, they will choose a different tool. They must. By testing the water elsewhere—as such a downtime would lead to—failure can encourage them to switch to the rival.
ACK when I communicated with Google, I came to realise that they have engineers whose sole/main purpose was to ensure the site stays online at all times. A few days ago I had another odd realisation, but perhaps a very obvious one. To search engines, downtimes are a hugely damaging thing. If people are unable to search for something immediately, they will choose a different tool. They must. By testing the water elsewhere—as such a downtime would lead to—failure can encourage them to switch to the rival.