
How does the notorious Google cookie affecting your search results?
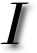 I is no secret that Webmasters sometimes subvert (or “optimise” as they would call it) Google results pages, which in turn weakens the relevance of Google’s search results. This manipulation is done by insertion/injection of particular keywords, as well as navigation hacks, ‘organic’ inbound links and so forth.
I is no secret that Webmasters sometimes subvert (or “optimise” as they would call it) Google results pages, which in turn weakens the relevance of Google’s search results. This manipulation is done by insertion/injection of particular keywords, as well as navigation hacks, ‘organic’ inbound links and so forth.
While artificial changes to site content have an effect on other search engines, changes are done primarily with Google in mind. This urges Google to make their strategy (algorithms) more dynamic and permit results to ‘dance’ every now and then, sometimes owing to large updates (c/f Bourbon). In such circumstances, ‘re-shuffle’ reached the extent that resembles a complete overhaul of indices. The main purpose it to weed out spam, yet the borderline between “ham” and “spam” becomes rather vague, so genuine siteget affected and often penalised. Many lose vital revenue as a consequence.
The Internet is becoming a brutal battelground. There are many cases of black-hat SEO, which have become worryingly prevalent. Even id search engines can annul the effect of ‘noise’, this does not account for the issue of relevance, spam aside. This is possibly a case of becoming a victim of one’s own success. Google have become the main target to many harmful practices, including the rumour mill.
In my humble opinion, Google remain the best engine bar none, but new challenges are being posed every day. Black-hat practices accumulate more and more tricks, which can be ‘pulled off the sleeve’ and then shared, soon to become a Web epidemic. Like a virus which quickly exploits flaws in servers and desktops, SEO hacks rely on flaws in search engines algorithms. The question remains: will Google be able to adapt to changes as soon as they occur, thereby annihilating the impact of Google-targetted site/page optimisations? I will illustrate using a very timely and true example.
This morning I wanted to know the precise definition and difference between single-breasted and double-breasted garments. Putting “single breasted double breasted” in Wikipedia (I tend to use it for knowledge queries, as opposed to URL search), I got the perfect answers with clarifications, pictures included. In Google, one gets promotional stuff. Shops are trying to sell suits, so results 1 to 4 are purely irrelevant for my query (at least the one I had in mind). I had no intention of seeking a guide or a purchase. In other words, the finanical incentive beat the informative source, which is sad. I did, however, find Wikipedia’s page at number on Google for the phrase “single breasted double breasted”. To me, this was not good enough. As a whole, it wasn’t a specific and satisfactory outcome as the first 4 places attempted to sell me something. Knowledge references should surpass any individual store — one among the many which exist.






 Filed under:
Filed under: 
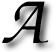 number of links that reach a given site can be probed (or estimated based on crawlers) using some special syntax in queries. The universally-accepted form for the query has become
number of links that reach a given site can be probed (or estimated based on crawlers) using some special syntax in queries. The universally-accepted form for the query has become 
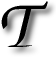 HERE is a growing interest in snatching of Web traffic from search engines. A notorious method for achieving this is by large mass of
HERE is a growing interest in snatching of Web traffic from search engines. A notorious method for achieving this is by large mass of 
 OMMERCIAL effects of search engines can no longer be ignored. Now that
OMMERCIAL effects of search engines can no longer be ignored. Now that 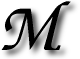 Y site has just returned to Google’s top 50 for “roy”, after I had dropped to oblivion last year. I was never truly trying to get there. I never aimed for the site to be affiliated with the keyword “roy”, but this was a side effect of anchor text (words adject to or within hyperlinks). More oddly, my domain name and front page title make no mentioning of Roy. This, anchor text must matter a great deal; More than many of us realise, that’s for sure.
Y site has just returned to Google’s top 50 for “roy”, after I had dropped to oblivion last year. I was never truly trying to get there. I never aimed for the site to be affiliated with the keyword “roy”, but this was a side effect of anchor text (words adject to or within hyperlinks). More oddly, my domain name and front page title make no mentioning of Roy. This, anchor text must matter a great deal; More than many of us realise, that’s for sure.
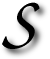 EARCHING of the Web is no exact science. If it was, its exhaustive exploration would be infeasible. The more formidable search engines amass information from million of Web sites, each containing huge lumps of information — both textual and media. That information, in turn, could be interpreted and/or indexed in a variety of different forms. Rarely is the content truly understood, which is my personal motivating for
EARCHING of the Web is no exact science. If it was, its exhaustive exploration would be infeasible. The more formidable search engines amass information from million of Web sites, each containing huge lumps of information — both textual and media. That information, in turn, could be interpreted and/or indexed in a variety of different forms. Rarely is the content truly understood, which is my personal motivating for  Still, everyone wants to discover the perfect recipe to outperforming Google. Others try to reverse-engineer their algorithms and cheat (fame and riches owing to ‘
Still, everyone wants to discover the perfect recipe to outperforming Google. Others try to reverse-engineer their algorithms and cheat (fame and riches owing to ‘